 |  |

| |
In addition
to the standard character sets discussed
previously, many vendors have at one time or another produced
proprietary character sets to meet the
needs of their specific platform. Often, they contain special
characters the vendor saw a need for, such as
Apple's trademarked open apple  or the box-drawing characters such as
or the box-drawing characters such as 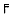 and
and 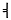 used for cell boundaries in early DOS spreadsheets. Microsoft, IBM, and Apple are the three most prolific inventors of character sets. The single most common such set is probably Microsoft's Cp1252, a variant of Latin-1 that replaces the C1 controls with more graphic characters. Hundreds of such platform-dependent character sets are in use today. Documentation for these ranges from excellent to nonexistent.
used for cell boundaries in early DOS spreadsheets. Microsoft, IBM, and Apple are the three most prolific inventors of character sets. The single most common such set is probably Microsoft's Cp1252, a variant of Latin-1 that replaces the C1 controls with more graphic characters. Hundreds of such platform-dependent character sets are in use today. Documentation for these ranges from excellent to nonexistent.
Platform-specific character sets like these should be used only
within a single system. They should never be placed on the wire or
used to transfer data between systems. Doing so can lead to nasty
surprises in unexpected places. For example, displaying a file that
contains some of the extra Cp1252 characters 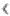 ,
,
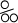 , ^,
, ^, 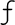 , ",
, ",
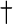 , ...,
, ..., 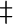 ,
, 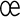 ,
,
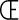 , ·, `,
', ", ", -,
--,
, ·, `,
', ", ", -,
--,  ,
, 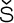 , ™,
, ™,  , and ~ on a VT-220 terminal can effectively disable the screen. Nonetheless, these character sets are in common use and often seen on the Web even when they don't belong there. There's no absolute rule that says you can't use them for an XML document, provided that you include the proper encoding declaration and your parser understands it. The one advantage to using these sets is that existing text editors are likely to be much more comfortable with them than with Unicode and its friends. Nonetheless, we strongly recommend that you don't use them and stick to the documented standards that are much more broadly supported across platforms.
, and ~ on a VT-220 terminal can effectively disable the screen. Nonetheless, these character sets are in common use and often seen on the Web even when they don't belong there. There's no absolute rule that says you can't use them for an XML document, provided that you include the proper encoding declaration and your parser understands it. The one advantage to using these sets is that existing text editors are likely to be much more comfortable with them than with Unicode and its friends. Nonetheless, we strongly recommend that you don't use them and stick to the documented standards that are much more broadly supported across platforms.
The most common platform-dependent character set, and the one
you're most likely to encounter on the Internet, is
Cp1252,
also (and incorrectly) known as Windows
ANSI. This is the default character set used by
most American and Western European Windows PCs, which explains its
ubiquity. Cp1252 is a single-byte character set almost identical to
the standard ISO-8859-1 character set--indeed, many Cp1252
documents are often incorrectly labeled as being Latin-1 documents.
However, this set replaces the C1 controls between code points 128
and 159 with additional graphics characters, such as
, , and . These
characters won't cause problems on other Windows
systems. However, other platforms will have difficulty viewing them
properly and may even crash in extreme cases. Cp1252 (and its
siblings used in non-Western Windows systems) should be avoided.
The Mac OS uses a different nonstandard, single-byte character set that's a superset of ASCII. The version used in the Americas and most of Western Europe is called MacRoman. Variants for other countries include MacGreek, MacHebrew, MacIceland, and so forth. Most Java-based XML processors can make sense out of these encodings if they're properly labeled, but most other non-Macintosh tools cannot.
For instance, if the French sentence "Au cours des dernières années, XML a été adapte dans des domaines aussi diverse que l'aéronautique, le multimédia, la gestion de hôpitaux, les télécommunications, la théologie, la vente au détail et la littérature médiévale" is written on a Macintosh and then read on a PC, what the PC user will see is "Au cours des derni?res annžes, XML a žtž adapte dans des domaines aussi diverse que l'ažronautique, le multimždia, la gestion de h™pitaux, les tžlžcommunications, la thžologie, la vente au džtail et la littžrature mždižvale," not the same thing at all. Generally, the result is at least marginally intelligible if most of the text is ASCII, but it certainly doesn't lend itself to high fidelity or quality. Mac-specific character sets should also be avoided.
|  | |
| 5.6. ISO Character Sets |  | 5.8. Converting Between Character Sets |

Copyright © 2002 O'Reilly & Associates. All rights reserved.