
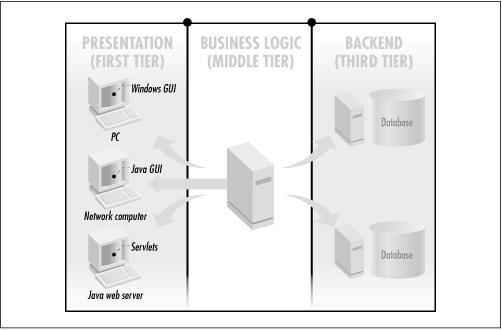
EJB is a component model for component transaction monitors, which are based on distributed object technologies. Therefore, to understand EJB you need to understand how distributed objects work. Distributed object systems are the foundation for modern three-tier architectures. In a three-tier architecture, as shown in Figure 1-1, the presentation logic resides on the client (first tier), the business logic on the middle tier (second tier), and other resources, such as the database, reside on the backend (third tier).
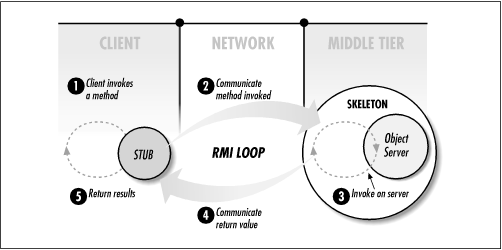
All distributed object protocols are built on the same basic architecture, which is designed to make an object on one computer look like it's residing on a different computer. Distributed object architectures are based on a network communication layer that is really very simple. Essentially, there are three parts to this architecture: the object server, the skeleton, and the stub.
The object server is the business object that resides on the middle tier. The term "server" can be a little confusing, but for our purposes the object on the middle tier can be called the "object server" to distinguish it from its counterparts, the stub and skeleton. The object server is an instance of an object with its own unique state. Every object server class has matching stub and skeleton classes built specifically for that type of object server. So, for example, a distributed business object called Person would have matching Person_Stub and Person_Skeleton classes. As shown in Figure 1-2, the object server and skeleton reside on the middle tier, and the stub resides on the client.
The stub and the skeleton are responsible for making the object server, which lives on the middle tier, look as if it is running locally on the client machine. This is accomplished through some kind of remote method invocation (RMI) protocol. An RMI protocol is used to communicate method invocations over a network. CORBA, Java RMI, and Microsoft DCOM all use their own RMI protocol.[3] Every instance of the object server on the middle tier is wrapped by an instance of its matching skeleton class. The skeleton is set up on a port and IP address and listens for requests from the stub. The stub resides on the client machine and is connected via the network to the skeleton. The stub acts as the object server's surrogate on the client and is responsible for communicating requests from the client to the object server through the skeleton. Figure 1-2 illustrates the process of communicating a method invocation from the client to the server object and back. The stub and the skeleton hide the communication specifics of the RMI protocol from the client and the implementation class, respectively.
[3] The acronym RMI isn't specific to Java RMI; it was in use long before Java came along. This section uses RMI to describe distributed object protocols in general. Java RMI is the Java language version of a distributed object protocol.
The stub implements an interface with the same business methods as the object itself, but the stub's methods do not contain business logic. Instead, the business methods on the stub implement whatever networking operations are required to forward the request to the object server and receive the results. When a client invokes a business method on the stub, the request is communicated over the network by streaming the name of the method invoked, and the values passed in as parameters, to the skeleton. When the skeleton receives the incoming stream, it parses the stream to discover which method is requested, and then invokes the corresponding business method on the object server. Any value that is returned from the method invoked on the object server is streamed back to the stub by the skeleton. The stub then returns the value to the client application as if it had processed the business logic locally.
The best way to illustrate how distributed objects work is to show how you can implement a distributed object yourself, with your own distributed object protocol. This will give you some appreciation for what a true distributed object protocol like CORBA does. Actual distributed object systems such as DCOM, CORBA, and Java RMI are, however, much more complex and robust than the simple example we will develop here. The distributed object system we develop in this chapter is only illustrative; it is not a real technology, nor is it part of Enterprise JavaBeans. The purpose is to provide you with some understanding of how a more sophisticated distributed object system works.
Here's a very simple distributed object called PersonServer that implements the Person interface. The Person interface captures the concept of a person business object. It has two business methods: getAge() and getName(). In a real application, we would probably define many more behaviors for the Person business object, but two methods are enough for this example:
public interface Person {
public int getAge() throws Throwable;
public String getName() throws Throwable;
}
The implementation of this interface, PersonServer, doesn't contain anything at all surprising. It defines the business logic and state for a Person:
public class PersonServer implements Person {
int age;
String name;
public PersonServer(String name, int age){
this.age = age;
this.name = name;
}
public int getAge(){
return age;
}
public String getName(){
return name;
}
}
Now we need some way to make the PersonServer available to a remote client. That's the job of the Person_Skeleton and Person_Stub. The Person interface describes the concept of a person independent of implementation. Both the PersonServer and the Person_Stub implement the Person interface because they are both expected to support the concept of a person. The PersonServer implements the interface to provide the actual business logic and state; the Person_Stub implements the interface so that it can look like a Person business object on the client and relay requests back to the skeleton, which in turn sends them to the object itself. Here's what the stub looks like:
import java.io.ObjectOutputStream;
import java.io.ObjectInputStream;
import java.net.Socket;
public class Person_Stub implements Person {
Socket socket;
public Person_Stub() throws Throwable {
// Create a network connection to the skeleton.
// Replace "myhost" with your own IP Address of your computer.
socket = new Socket("myhost",9000);
}
public int getAge() throws Throwable {
// When this method is invoked, stream the method name to the
// skeleton.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
outStream.writeObject("age");
outStream.flush();
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
return inStream.readInt();
}
public String getName() throws Throwable {
// When this method is invoked, stream the method name to the
// skeleton.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
outStream.writeObject("name");
outStream.flush();
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
return (String)inStream.readObject();
}
}
When a method is invoked on the Person_Stub, a String token is created and streamed to the skeleton. The token identifies the method that was invoked on the stub. The skeleton parses the method-identifying token, invokes the corresponding method on the object server, and streams back the result. When the stub reads the reply from the skeleton, it parses the value and returns it to the client. From the client's perspective, the stub processed the request locally. Now let's look at the skeleton:
import java.io.ObjectOutputStream;
import java.io.ObjectInputStream;
import java.net.Socket;
import java.net.ServerSocket;
public class Person_Skeleton extends Thread {
PersonServer myServer;
public Person_Skeleton(PersonServer server){
// Get a reference to the object server that this skeleton wraps.
this.myServer = server;
}
public void run(){
try {
// Create a server socket on port 9000.
ServerSocket serverSocket = new ServerSocket(9000);
// Wait for and obtain a socket connection from stub.
Socket socket = serverSocket.accept();
while (socket != null){
// Create an input stream to receive requests from stub.
ObjectInputStream inStream =
new ObjectInputStream(socket.getInputStream());
// Read next method request from stub. Block until request is
// sent.
String method = (String)inStream.readObject();
// Evaluate the type of method requested.
if (method.equals("age")){
// Invoke business method on server object.
int age = myServer.getAge();
// Create an output stream to send return values back to
// stub.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
// Send results back to stub.
outStream.writeInt(age);
outStream.flush();
} else if(method.equals("name")){
// Invoke business method on server object.
String name = myServer.getName();
// Create an output stream to send return values back to
// the stub.
ObjectOutputStream outStream =
new ObjectOutputStream(socket.getOutputStream());
// Send results back to stub.
outStream.writeObject(name);
outStream.flush();
}
}
} catch(Throwable t) {t.printStackTrace();System.exit(0); }
}
public static void main(String args [] ){
// Obtain a unique instance Person.
PersonServer person = new PersonServer("Richard", 34);
Person_Skeleton skel = new Person_Skeleton(person);
skel.start();
}
}
The Person_Skeleton routes requests received from the stub to the object server, PersonServer. Essentially, the Person_Skeleton spends all its time waiting for the stub to stream it a request. Once a request is received, it is parsed and delegated to the corresponding method on the PersonServer. The return value from the object server is then streamed back to the stub, which returns it as if it was processed locally.
Now that we've created all the machinery, let's look at a simple client that makes use of the Person:
public class PersonClient {
public static void main(String [] args){
try {
Person person = new Person_Stub();
int age = person.getAge();
String name = person.getName();
System.out.println(name+" is "+age+" years old");
} catch(Throwable t) {t.printStackTrace();}
}
}
This client application shows how the stub is used on the client. Except for the instantiation of the Person_Stub at the beginning, the client is unaware that the Person business object is actually a network proxy to the real business object on the middle tier. In Figure 1-3, the RMI loop diagram is changed to represent the RMI process as applied to our code.
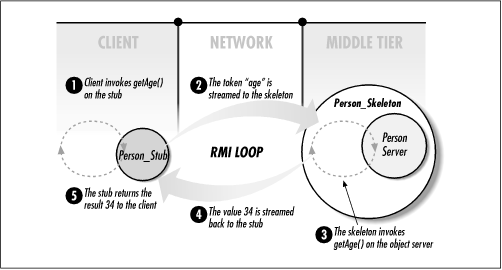
As you examine Figure 1-3, notice how the RMI loop was implemented by our distributed Person object. RMI is the basis of distributed object systems and is responsible for making distributed objects location transparent. Location transparency means that a server object's actual location--usually on the middle tier--is unknown and unimportant to the client using it. In this example, the client could be located on the same machine or on a different machine very far away, but the client's interaction with the business object is the same. One of the biggest benefits of distributed object systems is location transparency. Although transparency is beneficial, you cannot treat distributed objects as local objects in your design because of the performance differences. This book will provide you with good distributed object design strategies that take advantage of transparency while maximizing the distributed system's performance.
When this book talks about the stub on the client, we will often refer to it as a remote reference to the object server. This allows us to talk more directly about the object server and its representation on the client.
Distributed object protocols such as CORBA, DCOM, and Java RMI provide a lot more infrastructure for distributed objects than the Person example. Most implementations of distributed object protocols provide utilities that automatically generate the appropriate stubs and skeletons for object servers. This eliminates custom development of these constructs and allows a lot more functionality to be included in the stub and skeleton.
Even with automatic generation of stubs and skeletons, the Person example hardly scratches the surface of a sophisticated distributed object protocol. Real world protocols like Java RMI and CORBA IIOP provide error and exception handling, parameter passing, and other services like the passing of transaction and security context. In addition, distributed object protocols support much more sophisticated mechanisms for connecting the stub to the skeleton; the direct stub-to-skeleton connection in the Person example is fairly primitive.
Real distributed object protocols, like CORBA, also provide an Object Request Broker (ORB), which allows clients to locate and communicate with distributed objects across the network. ORBs are the communication backbone, the switchboard, for distributed objects. In addition to handling communications, ORBs generally use a naming system for locating objects and many other features such as reference passing, distributed garbage collection, and resource management. However, ORBs are limited to facilitating communication between clients and distributed object servers. While they may support services like transaction management and security, use of these services is not automatic. With ORBs, most of the responsibility for creating system-level functionality or incorporating services falls on the shoulders of the application developer.
 |  |  |
| 1.2. Enterprise JavaBeans: Defined |  | 1.4. Component Models |

Copyright © 2001 O'Reilly & Associates. All rights reserved.