
The Servlet Alternative
Servlet Reloading
Init and Destroy
Single-Thread Model
Background Processing
Last Modified Times
The servlet life cycle is one of the most exciting features of servlets. This life cycle is a powerful hybrid of the life cycles used in CGI programming and lower-level NSAPI and ISAPI programming, as discussed in Chapter 1, "Introduction".
The servlet life cycle allows servlet engines to address both the performance and resource problems of CGI and the security concerns of low-level server API programming. A servlet engine may execute all its servlets in a single Java virtual machine (JVM). Because they are in the same JVM, servlets can efficiently share data with each other, yet they are prevented by the Java language from accessing one another's private data. Servlets may also be allowed to persist between requests as object instances, taking up far less memory than full-fledged processes.
Before we proceed too far, you should know that the servlet life cycle is highly flexible. Servers have significant leeway in how they choose to support servlets. The only hard and fast rule is that a servlet engine must conform to the following life cycle contract:
Create and initialize the servlet.
Handle zero or more service calls from clients.
Destroy the servlet and then garbage collect it.
It's perfectly legal for a servlet to be loaded, created, and instantiated in its own JVM, only to be destroyed and garbage collected without handling any client requests or after handling just one request. Any servlet engine that makes this a habit, however, probably won't last long on the open market. In this chapter we describe the most common and most sensible life cycle implementations for HTTP servlets.
Most servlet engines want to execute all servlets in a single JVM. Where that JVM itself executes can differ depending on the server, though. With a server written in Java, such as the Java Web Server, the server itself can execute inside a JVM right alongside its servlets.
With a single-process, multithreaded web server written in another language, the JVM can often be embedded inside the server process. Having the JVM be part of the server process maximizes performance because a servlet becomes, in a sense, just another low-level server API extension. Such a server can invoke a servlet with a lightweight context switch and can provide information about requests through direct method invocations.
A multiprocess web server (which runs several processes to handle requests) doesn't really have the choice to embed a JVM directly in its process because there is no one process. This kind of server usually runs an external JVM that its processes can share. With this approach, each servlet access involves a heavyweight context switch reminiscent of FastCGI. All the servlets, however, still share the same external process.
Fortunately, from the perspective of the servlet (and thus from your perspective, as a servlet author), the server's implementation doesn't really matter because the server always behaves the same way.
We said above that servlets persist between requests as object instances. In other words, at the time the code for a servlet is loaded, the server creates a single class instance. That single instance handles every request made of the servlet. This improves performance in three ways:
It eliminates the object creation overhead that would otherwise be necessary to create a new servlet object. A servlet can be already loaded in a virtual machine when a request comes in, letting it begin executing right away.
It enables persistence. A servlet can have already loaded anything it's likely to need during the handling of a request. For example, a database connection can be opened once and used repeatedly thereafter. It can even be used by a group of servlets. Another example is a shopping cart servlet that loads in memory the price list along with information about its recently connected clients. Yet another servlet may choose to cache entire pages of output to save time if it receives the same request again.
Not only do servlets persist between requests, but so do any threads created by servlets. This perhaps isn't useful for the run-of-the-mill servlet, but it opens up some interesting possibilities. Consider the situation where one background thread performs some calculation while other threads display the latest results. It's quite similar to an animation applet where one thread changes the picture and another one paints the display.
To demonstrate the servlet life cycle, we'll begin with a simple example. Example 3-1 shows a servlet that counts and displays the number of times it has been accessed. For simplicity's sake, it outputs plain text.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class SimpleCounter extends HttpServlet {
int count = 0;
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain");
PrintWriter out = res.getWriter();
count++;
out.println("Since loading, this servlet has been accessed " +
count + " times.");
}
}
The code is simple--it just prints and increments the instance variable named count--but it shows the power of persistence. When the server loads this servlet, the server creates a single instance to handle every request made of the servlet. That's why this code can be so simple. The same instance variables exist between invocations and for all invocations.
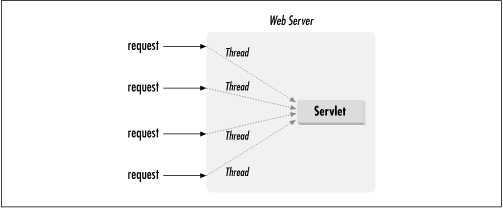
From the servlet-developer's perspective, each client is another thread that calls the servlet via the service(), doGet(), or doPost() methods, as shown in Figure 3-1.[1]
[1] Does it seem confusing how one servlet instance can handle multiple requests at the same time? If so, it's probably because when we picture an executing program we often see object instances performing the work, invoking each other's methods and so on. But, although this model works for simple cases, it's not how things actually work. In reality, all real work is done by threads. The object instances are nothing more than data structures manipulated by the threads. Therefore, if there are two threads running, it's entirely possible that both are using the same object at the same time.
If your servlets only read from the request, write to the response, and save information in local variables (that is, variables declared within a method), you needn't worry about the interaction among these threads. Once any information is saved in nonlocal variables (that is, variables declared within a class but outside any specific method), however, you must be aware that each of these client threads has the ability to manipulate a servlet's nonlocal variables. Without precautions, this may result in data corruption and inconsistencies. For example, the SimpleCounter servlet makes a false assumption that the counter incrementation and output occur atomically (immediately after one another, uninterrupted). It's possible that if two requests are made to SimpleCounter around the same time, each will print the same value for count. How? Imagine that one thread increments the count and just afterward, before the first thread prints the count, the second thread also increments the count. Each thread will print the same count value, after effectively increasing its value by 2.[2] The order of execution goes something like this
[2]Odd factoid: if count were a 64-bit long instead of a 32-bit int, it would be theoretically possible for the increment to be only half performed at the time it is interrupted by another thread. This is because Java uses a 32-bit wide stack.
count++ // Thread 1 count++ // Thread 2 out.println // Thread 1 out.println // Thread 2
Now, in this case, the inconsistency is obviously not a problem, but many other servlets have more serious opportunities for errors. To prevent these types of problems and the inconsistencies that come with them, we can add one or more synchronized blocks to the code. Anything inside a synchronized block or a synchronized method is guaranteed not to be executed concurrently by another thread. Before any thread begins to execute synchronized code, it must obtain a monitor(lock) on a specified class. If another thread already has that monitor--because it is already executing the same synchronized block or some other block with the same monitor--the first thread must wait. All this is handled by the language itself, so it's very easy to use. Synchronization, however, should be used only when necessary. On some platforms, it requires a fair amount of overhead to obtain the monitor each time a synchronized block is entered. More importantly, during the time one thread is executing synchronized code, the other threads may be blocked waiting for the monitor to be released.
For SimpleCounter, we have four options to deal with this potential problem. First, we could add the keyword synchronized to the doGet() signature:
public synchronized void doGet(HttpServletRequest req,
HttpServletResponse res)
This guarantees consistency by synchronizing the entire method, using the servlet class as the monitor. In general, though, this is not the right approach because it means the servlet can handle only one GET request at a time.
Our second option is to synchronize just the two lines we want to execute atomically:
PrintWriter out = res.getWriter();
synchronized(this) {
count++;
out.println("Since loading, this servlet has been accessed " +
count + " times.");
}
This approach works better because it limits the amount of time this servlet spends in its synchronized block, while accomplishing the same goal of a consistent count. Of course, for this simple example, it isn't much different than the first option.
Our third option is to create a synchronized block that performs all the work that needs to be done serially, then use the results outside the synchronized block. For our counter servlet, we can increment the count in a synchronized block, save the incremented value to a local variable (a variable declared inside a method), then print the value of the local variable outside the synchronized block:
PrintWriter out = res.getWriter();
int local_count;
synchronized(this) {
local_count = ++count;
}
out.println("Since loading, this servlet has been accessed " +
local_count + " times.");
This change shrinks the synchronized block to be as small as possible, while still maintaining a consistent count.
Our last option is to decide that we are willing to suffer the consequences of ignoring synchronization issues. Sometimes the consequences are quite acceptable. For this example, ignoring synchronization means that some clients may receive a count that's a bit off. Not a big deal, really. If this servlet were supposed to return unique numbers, however, it would be a different story.
Although it's not possible with this example, an option that exists for other servlets is to change instance variables into local variables. Local variables are not available to other threads and thus don't need to be carefully protected from corruption. At the same time, however, local variables are not persistent between requests, so we can't use them to store the persistent state of our counter.
Now, the "one instance per servlet" model is a bit of a gloss-over. The truth is that each registered name for a servlet (but not each alias) is associated with one instance of the servlet. The name used to access the servlet determines which instance handles the request. This makes sense because the impression to the client should be that differently named servlets operate independently. The separate instances are also a requirement for servlets that accept initialization parameters, as discussed later in this chapter.
Our SimpleCounter example uses the count instance variable to track the number of times it has been accessed. If, instead, it needed to track the count for all instances (and thus all registered aliases), it can in some cases use a class, or static, variable. These variables are shared across all instances of a class. Example 3-2 demonstrates with a servlet that counts three things: the times it has been accessed, the number of instances created by the server (one per name), and the total times all of them have been accessed.
import java.io.*;
import java.util.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HolisticCounter extends HttpServlet {
static int classCount = 0; // shared by all instances
int count = 0; // separate for each servlet
static Hashtable instances = new Hashtable(); // also shared
public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/plain");
PrintWriter out = res.getWriter();
count++;
out.println("Since loading, this servlet instance has been accessed " +
count + " times.");
// Keep track of the instance count by putting a reference to this
// instance in a Hashtable. Duplicate entries are ignored.
// The size() method returns the number of unique instances stored.
instances.put(this, this);
out.println("There are currently " +
instances.size() + " instances.");
classCount++;
out.println("Across all instances, this servlet class has been " +
"accessed " + classCount + " times.");
}
}
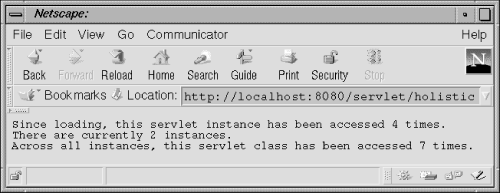
This HolisticCounter tracks its own access count with the count instance variable, the shared count with the classCount class variable, and the number of instances with the instances hashtable (another shared resource that must be a class variable). Sample output is shown in Figure 3-2.
 |  |  |
| 2.7. Moving On |  | 3.2. Servlet Reloading |

Copyright © 2001 O'Reilly & Associates. All rights reserved.