
 |  |
4.3. Protocols Above IP
IP serves as the base for a number of different protocols; by far the most common are TCP, UDP, and ICMP. In addition, we briefly discuss IP over IP (i.e., an IP packet encapsulated within another IP packet), which is used primarily for tunneling protocols over ordinary IP networks. This technique has been used in the past to tunnel multicast IP packets over nonmulticast IP networks, and more recently for a variety of virtual private networking systems, IPv6, and some systems for supporting mobile IP. These are the only IP-based protocols that you're likely to see being routed between networks outside a research environment.[9][9]You may also see the routing protocols OSPF or IGMP, which are discussed in Chapter 22, "Administrative Services". However, they are rarely distributed between networks and do not form the basis for other protocols.
4.3.1. TCP
TCP is the protocol most commonly used for services on the Internet. For example, Telnet, FTP, SMTP, NNTP, and HTTP are all TCP-based services. TCP provides a reliable, bidirectional connection between two endpoints. Opening a TCP connection is like making a phone call: you dial the number, and after a short setup period, a reliable connection is established between you and whomever you're calling.TCP is reliable in that it makes three guarantees to the application layer:
- The destination will receive the application data in the order it was sent.
- The destination will receive all the application data.
- The destination will not receive duplicates of any of the application data.
These guarantees incur certain costs in both setup time (the two sides of a connection have to exchange startup information before they can actually begin moving data) and ongoing performance (the two sides of a connection have to keep track of the status of the connection, to determine what data needs to be resent to the other side to fill in gaps in the conversation).
TCP is bidirectional in that once a connection is established, a server can reply to a client over the same connection. You don't have to establish one connection from a client to a server for queries or commands and another from the server back to the client for answers.
If you're trying to block a TCP connection, it is sufficient to simply block the first packet of the connection. Without that first packet (and, more importantly, the connection startup information it contains), any further packets in that connection won't be reassembled into a data stream by the receiver, and the connection will never be made. That first packet is recognizable because the ACK bit in its TCP header is not set; all other packets in the connection, regardless of which direction they're going in, will have the ACK bit set. (As we will discuss later, another bit, called the SYN bit, also plays a part in connection negotiation; it must be on in the first packet, but it can't be used to identify the first packet because it is also on in the second packet.)
Recognizing these "start-of-connection" TCP packets lets you enforce a policy that allows internal clients to connect to external servers but prevents external clients from connecting to internal servers. You do this by allowing start-of-connection TCP packets (those without the ACK bit set) only outbound and not inbound. Start-of-connection packets would be allowed out from internal clients to external servers but would not be allowed in from external clients to internal servers. Attackers cannot subvert this approach simply by turning on the ACK bit in their start-of-connection packets, because the absence of the ACK bit is what identifies these packets as start-of-connection packets.
Packet filtering implementations vary in how they treat and let you handle the ACK bit. Some packet filtering implementations give direct access to the ACK bit -- for example, by letting you include "ack" as a keyword in a packet filtering rule. Some other implementations give indirect access to the ACK bit. For example, the Cisco "established" keyword works by examining this bit (established is "true" if the ACK bit is set, and "false" if the ACK bit is not set). Finally, some implementations don't let you examine the ACK bit at all.
4.3.1.1. TCP options
The ACK bit is only one of the options that can be set; the whole list, in the order they appear in the header, is:
- URG (urgent)
- ACK (acknowledgment)
PSH (push)
RST (reset)
SYN (synchronize)
FIN (finish)
ACK and SYN together make up the famed TCP three-way handshake (so-called because it takes three packets to set up a connection). Figure 4-5 shows what ACK and SYN are set to on packets that are part of a TCP connection.
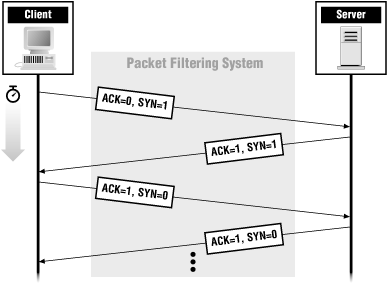
Figure 4-5. ACK bits on TCP packets
SYN is turned on for the first two packets of a connection (one in each direction), in order to set up sequence numbers. The first packet of a connection must have ACK off (since it isn't in response to anything) but SYN on (to give the next packet a number to acknowledge). Sequence numbers are discussed further in the section that follows.RST and FIN are ways of closing a connection. RST is an ungraceful close, sent to indicate that something has gone wrong (for instance, there's no process listening on the port, or there seems to be something nasty about the packet that came in). FIN is part of a graceful shutdown, where both ends send FIN to each other to say goodbye.
Of this entire laundry list, ACK and RST are the only two of interest to a firewall in normal operation (ACK because it is a reliable way to identify the first packet of connections, and RST because it's a useful way to shut people up without returning a helpful error message). However, there are a number of attacks that involve setting options that don't normally get set. Many TCP/IP implementations respond badly to eccentric combinations of options (for instance, they crash the machine). Others respond but don't log the fact, allowing attackers to scan networks without being noticed. These attacks are discussed further in the section that follows.
4.3.1.2. TCP sequence numbers
TCP provides a guarantee to applications that they will always receive data in the correct order, but nothing provides a guarantee to TCP that packets will always arrive in the correct order. In order to get the packets back into the correct order, TCP uses a number on each packet, called a sequence number. At the beginning of a connection, each end picks a number to start off with, and this number is what's communicated when SYN is set. There are two packets with SYN set (one in each direction), because the two ends maintain separate sequence numbers, chosen independently. After the SYN, for each packet, the number is simply incremented by the number of data bytes in the packet. If the first sequence number is 200, and the first data packet has 80 bytes of data on it, it will have a sequence number of 280.[10] The ACK is accompanied by the number of the next expected piece of data (the sequence number plus one, or 281 in this case).[10]The details of how the sequence number is calculated are actually slightly more complex than this, but the end result is as described.In order for an attacker to take over a TCP connection, the attacker needs to get the sequence numbers correct. Since sequence numbers are just incremented during a connection, this is easy for an attacker who can see the traffic. On the other hand, it's much more difficult if you can't see the initial negotiation; the initial sequence number is supposed to be randomly chosen. However, on many operating systems, initial sequence numbers are not actually random. In some TCP/IP implementations, initial sequence numbers are predictable; if you know what initial sequence number one connection uses, you can figure out what initial sequence number the next one will use, because the numbers are simply incremented, either based on number of connections (the number gets bigger by some fixed amount on each connection) or based on time (the number gets bigger by some fixed amount each microsecond).
This may seem like it's not worth worrying about. After all, in order to hijack a connection by predicting sequence numbers, an attacker needs:
- The ability to forge TCP/IP packets.
- The initial sequence number for one connection.
The knowledge that somebody else has started up a desirable connection (but not the ability to actually see that connection -- if the attacker can see the connection, there's no need to predict the sequence number).
- Precise information about when the desirable connection started up.
- Either the ability to redirect traffic so that you receive responses, or the ability to continue the conversation and achieve something without ever getting any of the responses.
4.3.2. UDP
The body of an IP packet might contain a UDP packet instead of a TCP packet. UDP is a low-overhead alternative to TCP.UDP is low overhead in that it doesn't make any of the reliability guarantees (delivery, ordering, and nonduplication) that TCP does, and, therefore, it doesn't need the mechanism to make those guarantees. Every UDP packet is independent; UDP packets aren't part of a "virtual circuit" as TCP packets are. Sending UDP packets is like dropping postcards in the mail: if you drop 100 postcards in the mail, even if they're all addressed to the same place, you can't be absolutely sure that they're all going to get there, and those that do get there probably won't be in exactly the same order they were in when you sent them. (As it turns out, UDP packets are far less likely to arrive than postcards -- but they are far more likely to arrive in the same order.)
Unlike postcards, UDP packets can actually arrive intact more than once. Multiple copies are possible because the packet might be duplicated by the underlying network. For example, on an Ethernet, a packet would be duplicated if a router thought that it might have been the victim of an Ethernet collision. If the router was wrong, and the original packet had not been the victim of a collision, both the original and the duplicate would eventually arrive at the destination. (An application may also decide to send the same data twice, perhaps because it didn't get an expected response to the first one, or maybe just because it's confused.)
All of these things can happen to TCP packets, too, but they will be corrected before the data is passed to the application. With UDP, the application is responsible for dealing with the data exactly as it arrives in packets, not corrected by the underlying protocol.
UDP packets are very similar to TCP packets in structure. A UDP header contains UDP source and destination port numbers, just like the TCP source and destination port numbers. However, a UDP header does not contain any of the flags or sequence numbers that TCP uses. In particular, it doesn't contain anything resembling an ACK bit. The ACK bit is part of TCP's mechanism for guaranteeing reliable delivery of data. Because UDP makes no such guarantees, it has no need for an ACK bit. There is no way for a packet filtering router to determine, simply by examining the header of an incoming UDP packet, whether that packet is a first packet from an external client to an internal server, or a response from an external server back to an internal client.
4.3.3. ICMP
ICMP is used for IP status and control messages. ICMP packets are carried in the body of IP packets, just as TCP and UDP packets are. Examples of ICMP messages include:
- Echo request
- What a host sends when you run ping.
- Echo response
- What a host responds to an "echo request" with.
- Time exceeded
- What a router returns when it determines that a packet appears to be looping. A more intuitive name might be maximum hopcount exceeded because it's based on the number of routers a packet has passed through, not a period of time.
- Destination unreachable
- What a router returns when the destination of a packet can't be reached for some reason (e.g., because a network link is down).
- Redirect
- What a router sends a host in response to a packet the host should have sent to a different router. The router handles the original packet anyway (forwarding it to the router it should have gone to in the first place), and the redirect tells the host about the more efficient path for next time.
any packet filtering systems let you filter ICMP packets based on the ICMP message type field, much as they allow you to filter TCP or UDP packets based on the TCP or UDP source and destination port fields. Relatively few of them allow you to filter on codes within a type. This is a problem because you will probably want to allow "Fragmentation needed and Don't Fragment set" (for path MTU discovery) but not any of the other codes under "Destination unreachable", all of which can be used to scan networks to see what hosts are attackable.
ost ICMP packets have little or no meaningful information in the body of the packet, and therefore should be quite small. However, various people have discovered denial of service attacks using oversized ICMP packets (particularly echo packets, otherwise known as "ping" packets after the Unix command normally used to send them). It is a good idea to put a size limit on any ICMP packet types you allow through your filters.
There have also been attacks that use ICMP as a covert channel, a way of smuggling information. As we mentioned previously, most ICMP packet bodies contain little or no meaningful information. However, they may contain padding, the content of which is undefined. For instance, if you use ICMP echo for timing or testing reasons, you will want to be able to vary the length of the packets and possibly the patterns of the data in them (some transmission mechanisms are quite sensitive to bit patterns, and speeds may vary depending on how compressible the data is, for instance). You are therefore allowed to put arbitrary data into the body of ICMP echo packets, and that data is normally ignored; it's not filtered, logged, or examined by anybody. For someone who wants to smuggle data through a firewall that allows ICMP echo, these bodies are a very tempting place to put it. They may even be able to smuggle data into a site that allows only outbound echo requests by sending echo responses even when they haven't seen a request. This will be useful only if the machine that the responses are being sent to is configured to receive them; it won't help anyone break into a site, but it's a way for people to maintain connections to compromised sites.
4.3.4. IP over IP and GRE
In some circumstances, IP packets are encapsulated within other IP packets for transmission, yielding so-called IP over IP. IP over IP is used for various purposes, including:
- Encapsulating encrypted network traffic; for instance, using the IPsec standard or PPTP, which are described in Chapter 14, "Intermediary Protocols".
- Carrying multicast IP packets (that is, packets with multicast destination addresses) between networks that do support multicasting over intermediate networks that don't
- Mobile IP (allowing a machine to move between networks while keeping a fixed IP address)
- Carrying IPv6 traffic over IPv4 networks
In some cases (for instance, for multicast and IPv6 traffic), the encapsulation and de-encapsulation is done by special routers. The sending and receiving machines send out their multicast or IPv6 traffic without knowing anything about the network in between, and when they get to a point where the network will not handle the special type, a router does the encapsulation. In this case, the encapsulated packet will be addressed to another router, which will unwrap it. The encapsulation may also be done by the sending machine or the de-encapsulation by the receiving machine.
IP over IP is also a common technique used for creating virtual private networks, which are discussed further in Chapter 5, "Firewall Technologies". It is the basis for a number of higher-level protocols, including IPsec and PPTP, which are discussed further in Chapter 14, "Intermediary Protocols".
IP over IP presents a problem for firewalls because the firewall sees the IP header information of the external packet, not the original information. In some cases, it is possible but difficult for the firewall to read the original headers; in other cases, the original packet information is encrypted, preventing it from being read by snoopers, but also by the firewall. This means that the firewall cannot make decisions about the internal packet, and there is a risk that it will pass traffic that should be denied. IP over IP should be permitted only when the destination of the external packet is a trusted host that will drop the de-encapsulated packet if it is not expected and permitted.
|  | |
| 4.2. IP |  | 4.4. Protocols Below IP |
