
 |  |
Chapter 13. Internet Services and Firewalls
Contents:
Attacks Against Internet ServicesEvaluating the Risks of a Service
Analyzing Other Protocols
What Makes a Good Firewalled Service?
Choosing Security-Critical Programs
Controlling Unsafe Configurations
The remaining chapters in Part III, "Internet Services" describe the major Internet services: how they work, what their packet filtering and proxying characteristics are, what their security implications are with respect to firewalls, and how to make them work with a firewall. The purpose of these chapters is to give you the information that will help you decide which services to offer at your site and to help you configure these services so they are as safe and as functional as possible in your firewall environment. We occasionally mention things that are not, in fact, Internet services but are related protocols, languages, or APIs that are often used in the Internet context or confused with genuine Internet services.
These chapters are intended primarily as a reference; they're not necessarily intended to be read in depth from start to finish, though you might learn a lot of interesting stuff by skimming this whole part of the book.
At this point, we assume that you are familiar with what the various Internet services are used for, and we concentrate on explaining how to provide those services through a firewall. For introductory information about what particular services are used for, see Chapter 2, "Internet Services".
Where we discuss the packet filtering characteristics of particular services, we use the same abstract tabular form we used to show filtering rules in Chapter 8, "Packet Filtering". You'll need to translate various abstractions like "internal", "external", and so on to appropriate values for your own configuration. See Chapter 8, "Packet Filtering" for an explanation of how you can translate abstract rules to rules for particular products and packages, as well as more information on packet filtering in general.
Where we discuss the proxy characteristics of particular services, we rely on concepts and terminology discussed in Chapter 9, "Proxy Systems".
Throughout the chapters in Part III, "Internet Services", we'll show how each service's packets flow through a firewall. The following figures show the basic packet flow: when a service runs directly (Figure 13-1) and when a proxy service is used (Figure 13-2). The other figures in these chapters show variations of these figures for individual services. If there are no specific figures for a particular service, you can assume that these generic figures are appropriate for that service.
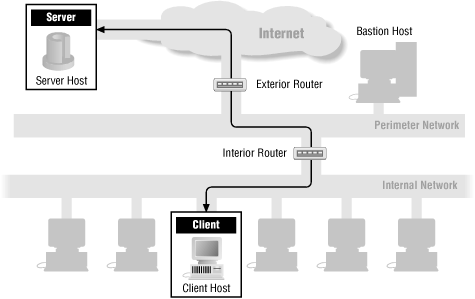
Figure 13-1. A generic direct service
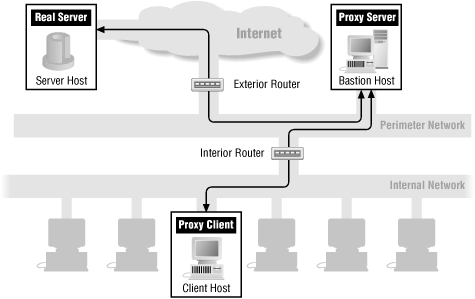
Figure 13-2. A generic proxy service
TIP: We frequently characterize client port numbers as "a random port number above 1023". Some protocols specify this as a requirement, and on others, it is merely a convention (spread to other platforms from Unix, where ports below 1024 cannot be opened by regular users). Although it is theoretically allowable for clients to use ports below 1024 on non-Unix platforms, it is extraordinarily rare: rare enough that many firewalls, including ones on major public sites that handle clients of all types, rely on this distinction and report never having rejected a connection because of it.
13.1. Attacks Against Internet Services
As we discuss Internet services and their configuration, certain concepts are going to come up repeatedly. These reflect the process of evaluating exactly what risks a given service poses. These risks can be roughly divided into two categories -- first, attacks that involve making allowed connections between a client and a server, including:
- Command-channel attacks
- Data-driven attacks
Third-party attacks
False authentication of clients
- Hijacking
- Packet sniffing
Data injection and modification
Replay
Denial of service
13.1.1. Command-Channel Attacks
A command-channel attack is one that directly attacks a particular service's server by sending it commands in the same way it regularly receives them (down its command channel). There are two basic types of command-channel attacks; attacks that exploit valid commands to do undesirable things, and attacks that send invalid commands and exploit server bugs in dealing with invalid input.If it's possible to use valid commands to do undesirable things, that is the fault of the person who decided what commands there should be. If it's possible to use invalid commands to do undesirable things, that is the fault of the programmer(s) who implemented the protocol. These are two separate issues and need to be evaluated separately, but you are equally unsafe in either case.
The original headline-making Internet problem, the 1988 Morris worm, exploited two kinds of command-channel attacks. It attacked Sendmail by using a valid debugging command that many machines had left enabled and unsecured, and it attacked finger by giving it an overlength command, causing a buffer overflow.
13.1.2. Data-Driven Attacks
A data-driven attack is one that involves the data transferred by a protocol, instead of the server that implements it. Once again, there are two types of data-driven attacks; attacks that involve evil data, and attacks that compromise good data. Viruses transmitted in electronic mail messages are data-driven attacks that involve evil data. Attacks that steal credit card numbers in transit are data-driven attacks that compromise good data.
13.1.3. Third-Party Attacks
A third-party attack is one that doesn't involve the service you're intending to support at all but that uses the provisions you've made to support one service in order to attack a completely different one. For instance, if you allow inbound TCP connections to any port above 1024 in order to support some protocol, you are opening up a large number of opportunities for third-party attacks as people make inbound connections to completely different servers.
13.1.4. False Authentication of Clients
A major risk for inbound connections is false authentication: the subversion of the authentication that you require of your users, so that an attacker can successfully masquerade as one of your users. This risk is increased by some special properties of passwords.In most cases, if you have a secret you want to pass across the network, you can encrypt the secret and pass it that way. That doesn't help if the information doesn't have to be understood to be used. For instance, encrypting passwords will not work because an attacker who is using packet sniffing can simply intercept and resend the encrypted password without having to decrypt it. (This is called a playback attack because the attacker records an interaction and plays it back later.) Therefore, dealing with authentication across the Internet requires something more complex than encrypting passwords. You need an authentication method where the data that passes across the network is nonreusable, so an attacker can't capture it and play it back.
Simply protecting you against playback attacks is not sufficient, either. An attacker who can find out or guess what the password is doesn't need to use a playback attack, and systems that prevent playbacks don't necessarily prevent password guessing. For instance, Windows NT's challenge/response system is reasonably secure against playback attacks, but the password actually entered by the user is the same every time, so if a user chooses to use "password", an attacker can easily guess what the password is.
Furthermore, if an attacker can convince the user that the attacker is your server, the user will happily hand over his username and password data, which the attacker can then use immediately or at leisure. To prevent this, either the client needs to authenticate itself to the server using some piece of information that's not passed across the connection (for instance, by encrypting the connection) or the server needs to authenticate itself to the client.
13.1.5. Hijacking
Hijacking attacks allow an attacker to take over an open terminal or login session from a user who has been authenticated and authorized by the system. Hijacking attacks generally take place on a remote computer, although it is sometimes possible to hijack a connection from a computer on the route between the remote computer and your local computer.How can you protect yourself from hijacking attacks on the remote computer? The only way is to allow connections only from remote computers whose security you trust; ideally, these computers should be at least as secure as your own. You can apply this kind of restriction by using either packet filters or modified servers. Packet filters are easier to apply to a collection of systems, but modified servers on individual systems allow you more flexibility. For example, a modified FTP server might allow anonymous FTP from any host, but authenticated FTP only from specified hosts. You can't get this kind of control from packet filtering. Under Unix, connection control at the host level is available from Wietse Venema's TCP Wrapper or from wrappers in TIS FWTK (the netacl program); these may be easier to configure than packet filters but provide the same level of discrimination -- by host only.
Hijacking by intermediate sites can be avoided using end-to-end integrity protection. If you use end-to-end integrity protection, intermediate sites will not be able to insert authentic packets into the data stream (because they don't know the appropriate key and the packets will be rejected) and therefore won't be able to hijack sessions traversing them. The IETF IPsec standard provides this type of protection at the IP layer under the name of "Authentication Headers", or AH protocol (RFC 2402). Application layer hijacking protection, along with privacy protection, can be obtained by adding a security protocol to the application; the most common choices for this are Transport Layer Security (TLS) or the Secure Socket Layer (SSL), but there are also applications that use the Generic Security Services Application Programming Interface (GSSAPI). For remote access to Unix systems the use of SSH can eliminate the risk of network-based session hijacking. IPsec, TLS, SSL, and GSSAPI are discussed further in Chapter 14, "Intermediary Protocols". ssh is discussed in Chapter 18, "Remote Access to Hosts".
Hijacking at the remote computer is quite straightforward, and the risk is great if people leave connections unattended. Hijacking from intermediate sites is a fairly technical attack and is only likely if there is some reason for people to target your site in particular. You may decide that hijacking is an acceptable risk for your own organization, particularly if you are able to minimize the number of accounts that have full access and the time they spend logged in remotely. However, you probably do not want to allow hundreds of people to log in from anywhere on the Internet. Similarly, you do not want to allow users to log in consistently from particular remote sites without taking special precautions, nor do you want users to log in to particularly secure accounts or machines from the Internet.
The risk of hijacking can be reduced by having an idle session policy with strict enforcement of timeouts. In addition, it's useful to have auditing controls on remote access so that you have some hope of noticing if a connection is hijacked.
13.1.6. Packet Sniffing
Attackers may not need to hijack a connection in order to get the information you want to keep secret. By simply watching packets pass -- anywhere between the remote site and your site -- they can see any unencrypted information that is being transferred. Packet sniffing programs automate this watching of packets.Sniffers may go after passwords or data. Different risks are associated with each type of attack. Protecting your passwords against sniffing is usually easy: use one of the several mechanisms described in Chapter 21, "Authentication and Auditing Services", to use nonreusable passwords. With nonreusable passwords, it doesn't matter if the password is captured by a sniffer; it's of no use to them because it cannot be reused.
Protecting your data against sniffers is more difficult. The data needs to be encrypted before it passes across the network. There are two means you might use for this kind of encryption; encrypting files that are going to be transferred, and encrypting communications links.
Encrypting files is appropriate when you are using protocols that transfer entire files (you're sending mail, using the Web, or explicitly transferring files), when you have a safe way to enter the information that will be used to encrypt them, and when you have a safe way to get the recipient the information needed to decrypt them. It's particularly useful if the file is going to cross multiple communications links, and you can't be sure that all of them will be secured, or if the file will spend time on hosts that you don't trust. For instance, if you're writing confidential mail on a laptop and using a public key encryption system, you can do the entire encryption on the machine you control and send on the entire encrypted file in safety, even if it will pass through multiple mail servers and unknown communications links.
Encrypting files won't help much if you're logging into a machine remotely. If you type in your mail on a laptop and encrypt it there, you're relatively safe. If you remotely log into a server from your laptop and then type in the mail and encrypt it, an attacker can simply watch you type it and may well be able to pick up any secret information that's involved in the encryption process.
In many situations, instead of encrypting the data in advance, it's more practical to encrypt the entire conversation. Either you can encrypt at the IP level via a virtual private network solution, or you can choose an encrypted protocol (for instance, SSH for remote shell access). We discuss virtual private networks in Chapter 5, "Firewall Technologies", and we discuss the availability of encrypted protocols as we describe each protocol in the following chapters.
These days, eavesdropping and encryption are both widespread. You should require encryption on inbound services unless you have some way to be sure that no confidential data passes across them. You may also want to encrypt outbound connections, particularly if you have any reason to believe that the information in them is sensitive.
13.1.7. Data Injection and Modification
An attacker who can't successfully take over a connection may be able to change the data inside the connection. An attacker that controls a router between a client and a server can intercept a packet and modify it, instead of just reading it. In rare cases, even an attacker that doesn't control a router can achieve this (by sending the modified packet in such a way that it will arrive before the original packet).Encrypting data won't protect you from this sort of attack. An attacker will still be able to modify the encrypted data. The attacker won't be able to predict what you'll get when you decrypt the data, but it certainly won't be what you expected. Encryption will keep an attacker from intentionally turning an order for 200 rubber chickens into an order for 2,000 rubber chickens, but it won't keep the attacker from turning the order into garbage that crashes your order input system. And you can't even be sure that the attacker won't turn the order into something else meaningful by accident.
Fully protecting services from modification requires some form of message integrity protection, where the packet includes a checksum value that is computed from the data and can't be recomputed by an attacker. Message integrity protection is discussed further in Appendix C, "Cryptography".
13.1.8. Replay
An attacker who can't take over a connection or change a connection may still be able to do damage simply by saving up information that has gone past and sending it again. We've already discussed one variation of this attack, involving passwords.There are two kinds of replays, ones in which you have to be able to identify certain pieces of information (for instance, the password attacks), and ones where you simply resend the entire packet. Many forms of encryption will protect you from attacks where the attacker is gathering information to replay, but they won't help you if it's possible to just reuse a packet without knowing what's in it.
Replaying packets doesn't work with TCP because of the sequence numbers, but there's no reason for it to fail with UDP-based protocols. The only protection against it is to have a protocol that will reject the replayed packet (for instance, by using timestamps or embedded sequence numbers of some sort). The protocol must also do some sort of message integrity checking to prevent an attacker from updating the intercepted packet.
13.1.9. Denial of Service
As we discussed in Chapter 1, "Why Internet Firewalls?", a denial of service attack is one where the attacker isn't trying to get access to information but is just trying to keep anybody else from having access. Denial of service attacks can take a variety of forms, and it is impossible to prevent all of them.Somebody undertaking a denial of service attack is like somebody who's determined to keep other people from accessing a particular library book. From the attackers' point of view, it's very desirable to have an attack that can't be traced back and that requires a minimum of effort (in a library, they implement this sort of effect by stealing all the copies of the book; on a network, they use source address forgery to exploit bugs). These attacks, however, tend to be preventable (in a library, you put in alarm systems; in a network, you filter out forged addresses). Other attacks require more effort and caution but are almost impossible to prevent. If a group of people bent on censorship coordinate their efforts, they can simply keep all the copies of a book legitimately checked out of the library. Similarly, a distributed attack can prevent other people from getting access to a service while using only legitimate means to reach the service.
Even though denial of service attacks cannot be entirely prevented, they can be made much more difficult to implement. First, servers should not become unavailable when invalid commands are issued. Poorly implemented servers may crash or loop in response to hostile input, which greatly simplifies the attacker's task. Second, servers should limit the resources allocated to any single entity. This includes:
- The number of open connections or outstanding requests
- The elapsed time a connection exists or a request is being processed
The amount of processor time spent on a connection or request
The amount of memory allocated to a connection or request
The amount of disk space allocated to a connection or request
13.1.10. Protecting Services
How well does a firewall protect against these different types of attacks?
- Command-channel attacks
- A firewall can protect against command-channel attacks by restricting the number of machines to which attackers can open command channels and by providing a secured server on those machines. In some cases, it can also filter out clearly dangerous commands (for instance, invalid commands or commands you have decided not to allow).
- Data-driven attacks
- A firewall can't do much about data-driven attacks; the data has to be allowed through, or you won't actually be able to do anything. In some cases, it's possible to filter out bad data. For instance, you can run virus scanners over email and other file transfer protocols. Your best bet, however, is to educate users to the risks they run when they bring files to their machine and when they send data out, and to provide appropriate tools allowing them to protect their computers and data. These include virus checkers and encryption software.
- Third-party attacks
- Third-party attacks can sometimes be prevented by the same sort of tactics used against command-channel attacks: limit the hosts that are accessible to ones where you know only the desired services are available, and/or do protocol checking to make certain that the commands you're getting are for the service you're trying to allow.
- False authentication of clients
- A firewall cannot prevent false authentication of clients. It can, however, limit incoming connections to ones on which you enforce the use of nonreusable passwords.
- Hijacking
- A firewall can rarely do anything about hijacking. Using a virtual private network with encryption will prevent it; so will protocols that use encryption with a shared secret between the client and the server, which will keep the hijacker from being able to send valid packets. Using TCP implementations that have highly unpredictable sequence numbers will decrease the possibility of hijacking TCP connections. It will not protect you from a hijacker that can see the legitimate traffic. Even somewhat unpredictable sequence numbers will help; hijacking attempts will create a burst of invalid packets that may be detectable by a firewall or an intrusion detection system. (Sequence numbers and hijacking are discussed in more detail in Chapter 4, "Packets and Protocols ".)
- Packet sniffing
- A firewall cannot do anything to prevent packet sniffing. Virtual private networks and encrypted protocols will not prevent packet sniffing, but they will make it less damaging.
- Data injection and modification
- There's very little a firewall can do about data injection or modification. A virtual private network will protect against it, as will a protocol that has message integrity checking.
- Replay
- Once again, a firewall can do very little about replay attacks. In a few cases, where there is literally a replay of exactly the same packet, a stateful packet filter may be able to detect the duplication; however, in many cases, it's perfectly reasonable for that to happen. The primary protection against replay attacks is using a protocol that's not vulnerable to them (one that involves message integrity and includes a timestamp, for instance).
- Denial of service
- Firewalls can help prevent denial of service attacks by filtering out forged or malformed requests before they reach servers. In addition, they can sometimes provide assistance by limiting the resources available to an attacker. For instance, a firewall can limit the rate with which it sends traffic to a server, or control the balance of allowed traffic so that a single source cannot monopolize services.
|  | |
| III. Internet Services |  | 13.2. Evaluating the Risks of a Service |
