

|
Chapter 2 Best Practices for Packages |

|
To build packages that are both immediately useful and enhanceable over the long-run, you must avoid any kind of code duplication inside the package. You need to be ready, willing, and able to create private programs in your package to contain all the shared code behind the public programs of the package. The alternative is a debilitating reliance on the Windows cut-and-paste feature. Cut-and-paste will let you build rapidly -- but what you will be building is a wide, deep hole from which you will never see the light of day.
I set a simple rule for myself when building packages: never repeat a line of code. Instead, construct a private module and call that module twice (or more, depending on the circumstances). By consolidating any reused logic rigorously, you have less code to debug and maintain. You will often end up with multiple layers of code right inside a single package. These layers will make it easier to enhance the package and also to build in additional functionality, such as the windows and toggles discussed earlier in this chapter.
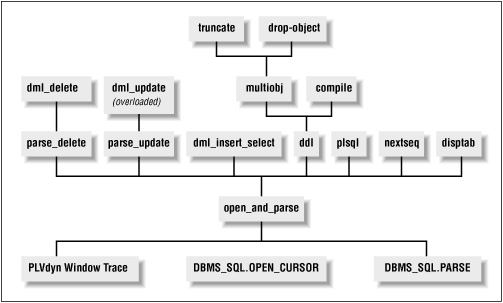
The PLVdyn package offers an example of in-package layering. As explained in the section on "Building Windows into Packages," the open_and_parse function consolidates the open and parse phases of dynamic SQL . This function is then called by many other higher-level operators in PLVdyn. These operators are in turn called by still other programs. The result is at least five layers of code as shown in Figure 2.2 .
NOTE: While it is uncommon, it is certainly possible for two programs to have the same name (and therefore be overloaded) but have little or nothing in common in their implementation. In this situation, you will probably not be able to consolidate the code in the package body for these two programs into a single, private program. There is nothing wrong with this situation (except that it might raise question of why you are using the same name for both programs).
The need for modularization inside a package is most clear when it comes to implementing overloaded programs. The next section will explore implementation strategies for overloading.
Overloading and modularization must be considered two sides of the same coin if you are going to implement your package properly. The previous section encouraged you to overload frequently and thoroughly. When you overload, you offer multiple versions of the same program. By doing so, you simplify the interface for the user, which is critical. At some point, however, you have to deal with the package body. If you've overloaded a particular procedure ten times, are you going to end up with ten completely separate procedure bodies and a large volume of redundant code that is very difficult to maintain?
Let's first understand the problem you can encounter inside packages when you overload. Consider that simplest (at first glance) of packages: the p package. You might be tempted to think that all it really does is provide a layer of code over the DBMS_OUTPUT.PUT_LINE built-in so that you can pass it more and different types of data. If that were the case, I could implement the p.l procedure as shown by the two of seven implementations below:
PROCEDURE l (char_in IN VARCHAR2, number_in IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE (char_in || ': ' || TO_CHAR (number_in)); END; PROCEDURE l (char_in IN VARCHAR2, date_in IN DATE, mask_in IN VARCHAR2 := PLV.datemask) IS BEGIN DBMS_OUTPUT.PUT_LINE (char_in || ': ' || TO_CHAR (date_in, mask_in)); END;
I have achieved the objective of overloading by taking on the job of combining the different pieces of data before passing it to the built-in package. No need for a private program shared by all the l procedures, is there? Well, that depends on just how useful you want that package to be.
Let's pretend that it is July 1994. I am writing Oracle PL/SQL Programming and just beginning to get a handle on packages. The p package (at that time called the do package) is one of my first and I throw it together, just as you see it above: a "raw" call to DBMS_OUTPUT. Then I start to use it to debug the PLVlst package (as it first appeared in that book) and at some point pass it a string with 463 characters. Suddenly, my program is generating a VALUE_ERROR exception. After a hour of debugging, I realize that the problem is not occurring in PLVlst, but in my p package. The DBMS_OUTPUT.PUT_LINE program cannot handle values with more than 255 bytes. I mutter venomously about the brain-dead implementations proffered at times by Oracle Corporation and quickly move to fix the problem, as you can see below:
PROCEDURE l (char_in IN VARCHAR2, number_in IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE (SUBSTR (char_in || ': ' || TO_CHAR (number_in), 1, 255)); END; PROCEDURE l (char_in IN VARCHAR2, date_in IN DATE, mask_in IN VARCHAR2 := PLV.datemask) IS BEGIN DBMS_OUTPUT.PUT_LINE (SUBSTR (char_in || ': ' || TO_CHAR (date_in, mask_in), 1, 255)); END;
Remember, I do this for all eight versions of the l procedure, not just the two you see. Well, that certainly takes care of that problem! So I continue my debugging and soon discover that when I ask DBMS_OUTPUT.PUT_LINE to display a NULL value or any string that LTRIMs to NULL, it just ignores me. I do not see a blank line; it just pretends that I never made the call. This is very confusing and irritating, but again the fix is clear: use the NVL operator. So now each of the l procedures looks like this:
PROCEDURE l (char_in IN VARCHAR2, number_in IN NUMBER) IS BEGIN DBMS_OUTPUT.PUT_LINE (NVL (SUBSTR (char_in || ': ' || TO_CHAR (number_in), 1, 255), 'NULL')); END; PROCEDURE l (char_in IN VARCHAR2, date_in IN DATE, mask_in IN VARCHAR2 := PLV.datemask) IS BEGIN DBMS_OUTPUT.PUT_LINE (NVL (SUBSTR (char_in || ': ' || TO_CHAR (date_in, mask_in), 1, 255), 'NULL')); END;
On and on I go, discovering new wrinkles in the implementation of DBMS_OUTPUT.PUT_LINE and scrambling to compensate in each of my eight procedures (see Chapter 6, PLV: Top-Level Constants and Functions , for more details on these wrinkles). Eventually each of my l procedures grows very convoluted, very similar to all the others, and very tedious to maintain. This is clearly not the way to go.
Now compare that process with the final state of the p package. Each of the l procedures consists of exactly one line of code, as you can see below:
PROCEDURE l (char_in IN VARCHAR2, number_in IN NUMBER, show_in IN BOOLEAN := FALSE) IS BEGIN display_line (show_in, char_in || ': ' || TO_CHAR (number_in)); END; PROCEDURE l (char_in IN VARCHAR2, date_in IN DATE, mask_in IN VARCHAR2 := PLV.datemask, show_in IN BOOLEAN := FALSE) IS BEGIN display_line (show_in, char_in || ': ' || TO_CHAR (date_in, mask_in)); END;
Only two actions are performed inside the l procedure:
Create the string to be displayed (usually occurring right inside the call to display_line ), and
Call the private module, display_line , to handle all the other issues.
The display_line procedure, in turn, looks like this:
PROCEDURE display_line (show_in IN VARCHAR2, line_in IN VARCHAR2) IS v_maxline INTEGER := 80; BEGIN IF v_show OR show_in THEN IF RTRIM (line_in) IS NULL THEN put_line (v_prefix || PLV.nullval); ELSIF LTRIM (RTRIM (line_in)) = v_linesep THEN put_line (v_prefix); ELSIF LENGTH (line_in) > v_maxline THEN PLVprs.display_wrap (line_in, v_maxline-5, NULL); ELSE put_line (v_prefix || SUBSTR (line_in, 1, c_max_dopl_line-v_prefix_len)); END IF; END IF; END;
Wow! It got really complicated, didn't it? In the final version of p.l , in fact, you can turn off the display of information using the built-in toggle. You can display long lines in paragraph-wrapped format. You can identify a character as a line separator so that white space can be preserved inside stored code and displayed as true blank lines in SQL*Plus.
I didn't come up with all of these features in a single flash of inspiration. I built them in over a period of months. Once I had transferred all common logic into the display_line procedure, however, it was a cinch to provide significant new functionality: I only had to make the changes in one location in my package . No user of the p package ever calls the display_line procedure; it is hidden. It exists only to consolidate all the common logic for displaying information.
I use this same approach throughout PL/Vision. Again and again, you will see the many overloadings of the package specification reduced to a single program inside the package body. I like to think of this of the overload-modularize diamond for packages, which is shown in Figure 2.3 . The upper point of the diamond is the user view: a single action (i.e., overloaded name) known and called by the user. The facets of the diamond broaden out to the different, overloaded programs in the specification. The lower point of the diamond represents the narrowing of the different programs to a single private program in the package body.
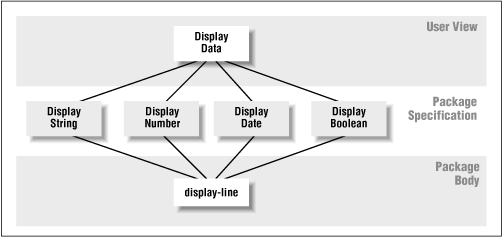
Sometimes creating this diamond shape in your packaged code is straightforward. The p package illustrates this simple case. The only difference between each of the overloaded programs is the way the string is constructed for display. In other packages, it takes lots more thought and creative programming to come up with a way to conform to my "only in one place" rule. The PLVtab package is such a package; in fact, the complexity of modularizing the internals of PLVtab resulted in what I call the lava lamp effect .
The objective of PLVtab is to make it easier for developers to use PL/SQL tables, particularly when it comes to displaying the contents of these tables. PLVtab predefines a set of table TYPE structures, such as tables of numbers, strings of various lengths, Booleans, and dates. It then offers a separate display procedure for each of the table TYPEs. Since each table TYPE is a different datatype, a separate, overloaded program is needed for each TYPE. The headers for two of these follow:
PROCEDURE display (table_in IN number_table, end_row_in IN INTEGER, header_in IN VARCHAR2 := NULL, start_row_in IN INTEGER := 1, failure_threshold_in IN INTEGER := 0, increment_in IN INTEGER := +1); PROCEDURE display (table_in IN vc30_table, end_row_in IN INTEGER, header_in IN VARCHAR2 := NULL, start_row_in IN INTEGER := 1, failure_threshold_in IN INTEGER := 0, increment_in IN INTEGER := +1);
As you can see from all of the parameters in the display procedures, PLVtab offers lots of flexibility in what you display and how you display it. This kind of flexibility always means a more complex implementation behind the scene in the package body. In fact, I use 184 lines of code spread across two private procedures to handle all the logic. Yet the body of each display procedure consists of just three lines as illustrated by the number_table display procedure below:
PROCEDURE display (table_in IN number_table, end_row_in IN INTEGER, header_in IN VARCHAR2 := NULL, start_row_in IN INTEGER := 1, failure_threshold_in IN INTEGER := 0, increment_in IN INTEGER := +1) IS BEGIN internal_number := table_in; internal_display (c_number, end_row_in, header_in, start_row_in, failure_threshold_in, increment_in); internal_number := empty_number; END;
The first line copies the incoming table to a private PL/SQL table of the same type; the second line calls the consolidated, internal version of the display program; and the third line empties the private PL/SQL table to minimize memory utilization. These same three lines appear in each of the nine display procedures, the only difference being the type of the private PL/SQL table and the first argument in the call to internal_display . This value tells internal_display which table is to be displayed. This approach allows me to create the lower point of my diamond: a single program called by each display program.
The difference in this case -- what I call the lava lamp effect -- is that deep within the internal_display procedure, I broaden out my code again (creating a base for my lava lamp; see Figure 2.4 ) with a large IF statement.
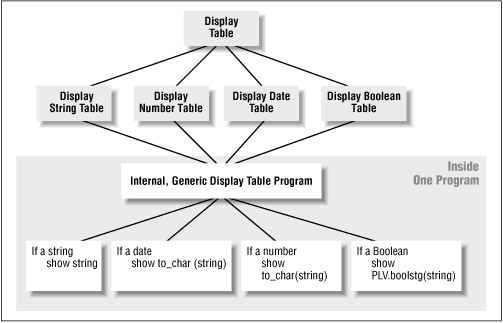
The main algorithm of internal_display is this WHILE loop:
WHILE in_range (current_row) AND within_threshold LOOP display_row (type_in, failure_threshold_in, increment_in, count_misses, current_row, within_threshold); END LOOP;
which translates roughly as "display each row within the specified range." The display_row is another private procedure that converts the type_in argument (the type of table being displayed) and the current_row into the row value to be displayed. To do this, it uses a big IF statement, a portion of which is shown here:
... ELSIF type_in = c_date THEN rowval := TO_CHAR (internal_date (current_row), PLV.datemask); ELSIF type_in = c_integer THEN rowval := TO_CHAR (internal_integer (current_row)); ELSIF type_in = c_number THEN rowval := TO_CHAR (internal_number (current_row)); ELSIF type_in = c_vc30 THEN rowval := internal_vc30 (current_row); ...
The overloading and modularization in PLVtab (and PLVgen as well) reminds me of playing an accordion: First, I squeeze in to present a single program for the user. Then I pull out to define the many overloadings in the specification. Squeeze back in to implement all those overloadings with a single private module. Pull back out inside that private module to handle all the different types of data. It may seem like a convoluted road to travel, but the end result is code that is very easily maintained, enhanced, and expanded.
As an exercise for the reader, I suggest that you perform this exercise: make a copy of PLVtab.sps and PLVtab.spb and see if you can figure out the steps required to add support for another type of PL/SQL table.
|
|

|
|
| 2.8 Overloading for Smart Packages |
|
2.10 Hiding Package Data |
Copyright (c) 2000 O'Reilly & Associates. All rights reserved.