 |
Chapter 3 Output from the Common Gateway Interface |
 |

|
Chapter 3 Output from the Common Gateway Interface |
|
Thus far, we've only seen examples with partial HTTP headers. That is, when all you include is a Content-type header, the server intercepts the output and completes the header information with header information of its own. The header information generated by the server might include a "200 OK" status code (if you haven't overridden it with a Status header), the date and time, the version of the server, and any other information that it thinks a browser might find useful.
But as we mentioned in Chapter 1 CGI programs can override the header information generated by the server by generating a complete HTTP header on its own.
Why go to all the trouble of generating your own header? When your program returns a complete HTTP header, there is no extra overhead incurred by the server. Instead, the output of the CGI program goes directly to the client, as shown in Figure 3.2. This may mean faster response time for the user. However, it also means you need to be especially careful when generating your own headers, since the server won't be able to circumvent any errors.
How does the server know if the CGI program has output a partial or a complete HTTP header without "looking" at it? It depends on which server you use. On the NCSA and CERN servers, programs that output complete headers must start with the "nph-" prefix (e.g., nph-test.pl), which stands for Non-Parsed Header.
The following example illustrates the usefulness of creating an NPH script:
#!/usr/local/bin/perl
$server_protocol = $ENV{'SERVER_PROTOCOL'};
$server_software = $ENV{'SERVER_SOFTWARE'};
print "$server_protocol 200 OK", "\n";
print "Server: $server_software", "\n";
print "Content-type: text/plain", "\n\n";
print "OK, Here I go. I am going to count from 1 to 50!", "\n";
$| = 1;
for ($loop=1; $loop <= 50; $loop++) {
print $loop, "\n";
sleep (2);
}
print "All Done!", "\n";
exit (0);
When you output a complete header, you should at least return header lines consisting of the HTTP protocol revision and the status of the program, the server name/version (e.g., NCSA/1.4.2), and the MIME content type of the data.
You can run this program by opening the URL to:
http://your.machine/cgi-bin/nph-count.pl
When you run this CGI script, you should see the output in "real time": the client will display the number, wait two seconds, display the next number, etc.
Now remove the complete header information (except for Content-type), change the name to count.pl (instead of nph-count.pl), and run it again. What's the difference? You will no longer see the output in "real time"; the client will display the entire document at once.
|
 |
|
| Status Codes |  |
Forms and CGI |
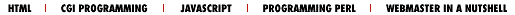
![[Graphic: Figure 3-2]](./figs/cgi0302.gif)