 |  |

| |
XSLT processors, like other XML tools, can read their input data from many different sources. In the most basic scenario, you will load a static stylesheet and XML document using the java.io.File class. More commonly, the XSLT stylesheet will come from a file, but the XML data will be generated dynamically as the result of a database query. In this case, it does not make sense to write the database query results to an XML file and then parse it into the XSLT processor. Instead, it is desirable to pipe the XML data directly into the processor using SAX or DOM. In fact, we will even see how to read nonXML data and transform it using XSLT.
The simple examples presented earlier in this chapter introduced the concept of a system identifier. As mentioned before, system identifiers are nothing more than URIs and are used frequently by XML tools. For example, javax.xml.transform.Source, one of the key interfaces in JAXP, has the following API:
public interface Source {
String getSystemId( );
void setSystemId(String systemId);
}The second method, setSystemId( ), is crucial. By providing a URI to the Source, the XSLT processor can resolve URIs encountered in XSLT stylesheets. This allows XSLT code like this to work:
<xsl:import href="commonFooter.xslt"/>
When it comes to XSLT programming, you will use methods in java.io.File and java.net.URL to convert platform-specific file names into system IDs. These can then be used as parameters to any methods that expect a system ID as a parameter. For example, you would write the following code to convert a platform-specific filename into a system ID:
public static void main(String[] args) {
// assume that the first command-line arg contains a file name
// - on Windows, something like "C:\home\index.xml"
// - on Unix, something like "/usr/home/index.xml"
String fileName = args[0];
File fileObject = new File(fileName);
URL fileURL = fileObject.toURL( );
String systemID = fileURL.toExternalForm( );This code was written on several lines for clarity; it can be consolidated as follows:
String systemID = new File(fileName).toURL().toExternalForm( );
Converting from a system identifier back to a filename or a File object can be accomplished with this code:
URL url = new URL(systemID); String fileName = url.getFile( ); File fileObject = new File(fileName);
And once again, this code can be condensed into a single line as follows:
File fileObject = new File((new URL(systemID)).getFile( ));
The Source and Result interfaces in javax.xml.transform provide the basis for all transformation input and output in JAXP 1.1. Regardless of whether a stylesheet is obtained via a URI, filename, or InputStream, its data is fed into JAXP via an implementation of the Source interface. The output is then sent to an implementation of the Result interface. The implementations provided by JAXP are shown in Figure 5-3.
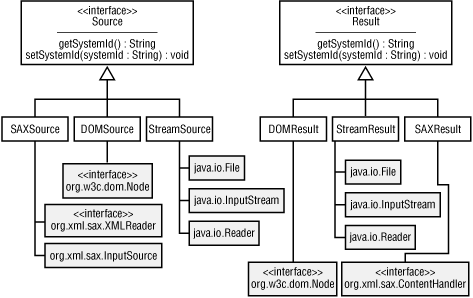
As you can see, JAXP is not particular about where it gets its data or sends its results. Remember that two instances of Source are always specified: one for the XML data and another for the XSLT stylesheet.
As shown in Figure 5-3, StreamSource is one of the implementations of the Source interface. In addition to the system identifiers that Source provides, StreamSource allows input to be obtained from a File, an InputStream, or a Reader. The SimpleJaxp class in Example 5-3 showed how to use StreamSource to read from a File object. There are also four constructors that allow you to construct a StreamSource from either an InputStream or Reader. The complete list of constructors is shown here:
public StreamSource( ) public StreamSource(File f) public StreamSource(String systemId) public StreamSource(InputStream byteStream) public StreamSource(InputStream byteStream, String systemId) public StreamSource(Reader characterStream) public StreamSource(Reader characterStream, String systemId)
For the constructors that take InputStream and Reader as arguments, the first argument provides either the XML data or the XSLT stylesheet. The second argument, if present, is used to resolve relative URI references in the document. As mentioned before, your XSLT stylesheet may include the following code:
<xsl:import href="commonFooter.xslt"/>
By providing a system identifier as a parameter to the StreamSource, you are telling the XSLT processor where to look for commonFooter.xslt. Without this parameter, you may encounter an error when the processor cannot resolve this URI. The simple fix is to call the setSystemId( ) method as follows:
// construct a Source that reads from an InputStream Source mySrc = new StreamSource(anInputStream); // specify a system ID (a String) so the Source can resolve relative URLs // that are encountered in XSLT stylesheets mySrc.setSystemId(aSystemId);
The documentation for StreamSource also advises that InputStream is preferred to Reader because this allows the processor to properly handle the character encoding as specified in the XML declaration.
StreamResult is similar in functionality to StreamSource, although it is not necessary to resolve relative URIs. The available constructors are as follows:
public StreamResult( ) public StreamResult(File f) public StreamResult(String systemId) public StreamResult(OutputStream byteStream) public StreamResult(Writer characterStream)
Let's look at some of the other options for StreamSource and StreamResult. Example 5-4 is a modification of the SimpleJaxp program that was presented earlier. It downloads the XML specification from the W3C web site and stores it in a temporary file on your local disk. To download the file, construct a StreamSource with a system identifier as a parameter. The stylesheet is a simple one that merely performs an identity transformation, copying the unmodified XML data to the result tree. The result is then sent to a StreamResult using its File constructor.
package chap5;
import java.io.*;
import javax.xml.transform.*;
import javax.xml.transform.stream.*;
/**
* A simple demo of JAXP 1.1 StreamSource and StreamResult. This
* program downloads the XML specification from the W3C and prints
* it to a temporary file.
*/
public class Streams {
// an identity copy stylesheet
private static final String IDENTITY_XSLT =
"<xsl:stylesheet xmlns:xsl='http://www.w3.org/1999/XSL/Transform'"
+ " version='1.0'>"
+ "<xsl:template match='/'><xsl:copy-of select='.'/>"
+ "</xsl:template></xsl:stylesheet>";
// the XML spec in XML format
// (using an HTTP URL rather than a file URL)
private static String xmlSystemId =
"http://www.w3.org/TR/2000/REC-xml-20001006.xml";
public static void main(String[] args) throws IOException,
TransformerException {
// show how to read from a system identifier and a Reader
Source xmlSource = new StreamSource(xmlSystemId);
Source xsltSource = new StreamSource(
new StringReader(IDENTITY_XSLT));
// send the result to a file
File resultFile = File.createTempFile("Streams", ".xml");
Result result = new StreamResult(resultFile);
System.out.println("Results will go to: "
+ resultFile.getAbsolutePath( ));
// get the factory
TransformerFactory transFact = TransformerFactory.newInstance( );
// get a transformer for this particular stylesheet
Transformer trans = transFact.newTransformer(xsltSource);
// do the transformation
trans.transform(xmlSource, result);
}
}The "identity copy" stylesheet simply matches "/", which is the document itself. It then uses <xsl:copy-of select='.'/> to select the document and copy it to the result tree. In this case, we coded our own stylesheet. You can also omit the XSLT stylesheet altogether as follows:
// construct a Transformer without any XSLT stylesheet Transformer trans = transFact.newTransformer( );
In this case, the processor will provide its own stylesheet and do the same thing that our example does. This is useful when you need to use JAXP to convert a DOM tree to XML text for debugging purposes because the default Transformer will simply copy the XML data without any transformation.
In many cases, the fastest form of transformation available is to feed an instance of org.w3c.dom.Document directly into JAXP. Although the transformation is fast, it does take time to generate the DOM; DOM is also memory intensive, and may not be the best choice for large documents. In most cases, the DOM data will be generated dynamically as the result of a database query or some other operation (see Chapter 1, "Introduction "). Once the DOM is generated, simply wrap the Document object in a DOMSource as follows:
org.w3c.dom.Document domDoc = createDomDocument( ); Source xmlSource = new javax.xml.transform.dom.DOMSource(domDoc);
The remainder of the transformation looks identical to the file-based transformation shown in Example 5-4. JAXP needs only the alternate input Source object shown here to read from DOM.
XSLT is designed to transform well-formed XML data into another format, typically HTML. But wouldn't it be nice if we could also use XSLT stylesheets to transform nonXML data into HTML? For example, most spreadsheets have the ability to export their data into Comma Separated Values (CSV) format, as shown here:
Burke,Eric,M Burke,Jennifer,L Burke,Aidan,G
One approach is parsing the file into memory, using DOM to create an XML representation of the data, and then feeding that information into JAXP for transformation. This approach works but requires an intermediate programming step to convert the CSV file into a DOM tree. A better option is to write a custom SAX parser, feeding its output directly into JAXP. This avoids the overhead of constructing the DOM tree, offering better memory utilization and performance.
It turns out that writing a SAX parser is quite easy.[21] All a SAX parser does is read an XML file top to bottom and fire event notifications as various elements are encountered. In our custom parser, we will read the CSV file top to bottom, firing SAX events as we read the file. A program listening to those SAX events will not realize that the data file is CSV rather than XML; it sees only the events. Figure 5-4 illustrates the conceptual model.
[21] Our examples use SAX 2.
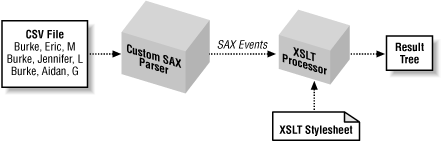
In this model, the XSLT processor interprets the SAX events as XML data and uses a normal stylesheet to perform the transformation. The interesting aspect of this model is that we can easily write custom SAX parsers for other file formats, making XSLT a useful transformation language for just about any legacy application data.
In SAX, org.xml.sax.XMLReader is a standard interface that parsers must implement. It works in conjunction with org.xml.sax.ContentHandler, which is the interface that listens to SAX events. For this model to work, your XSLT processor must implement the ContentHandler interface so it can listen to the SAX events that the XMLReader generates. In the case of JAXP, javax.xml.transform.sax.TransformerHandler is used for this purpose.
Obtaining an instance of TransformerHandler requires a few extra programming steps. First, create a TransformerFactory as usual:
TransformerFactory transFact = TransformerFactory.newInstance( );
As before, the TransformerFactory is the JAXP abstraction to some underlying XSLT processor. This underlying processor may not support SAX features, so you have to query it to determine if you can proceed:
if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {If this returns false, you are out of luck. Otherwise, you can safely downcast to a SAXTransformerFactory and construct the TransformerHandler instance:
SAXTransformerFactory saxTransFact =
(SAXTransformerFactory) transFact;
// create a ContentHandler, don't specify a stylesheet. Without
// a stylesheet, raw XML is sent to the output.
TransformerHandler transHand = saxTransFact.newTransformerHandler( );In the code shown here, a stylesheet was not specified. JAXP defaults to the identity transformation stylesheet, which means that the SAX events will be "transformed" into raw XML output. To specify a stylesheet that performs an actual transformation, pass a Source to the method as follows:
Source xsltSource = new StreamSource(myXsltSystemId);
TransformerHandler transHand = saxTransFact.newTransformerHandler(
xsltSource);Before delving into the complete example program, let's step back and look at a more detailed design diagram. The conceptual model is straightforward, but quite a few classes and interfaces come into play. Figure 5-5 shows the pieces necessary for SAX-based transformations.
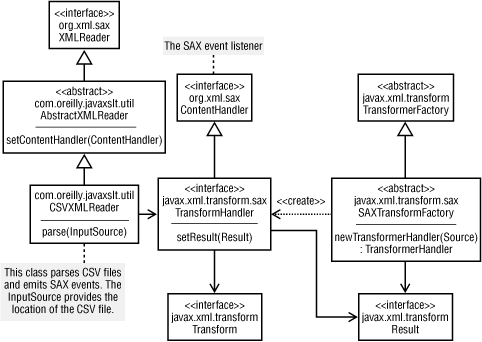
This diagram certainly appears to be more complex than previous approaches, but is similar in many ways. In previous approaches, we used the TransformerFactory to create instances of Transformer; in the SAX approach, we start with a subclass of TransformerFactory. Before any work can be done, you must verify that your particular implementation supports SAX-based transformations. The reference implementation of JAXP does support this, although other implementations are not required to do so. In the following code fragment, the getFeature method of TransformerFactory will return true if you can safely downcast to a SAXTransformerFactory instance:
TransformerFactory transFact = TransformerFactory.newInstance( );
if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {
// downcast is allowed
SAXTransformerFactory saxTransFact = (SAXTransformerFactory) transFact;If getFeature returns false, your only option is to look for an implementation that does support SAX-based transformations. Otherwise, you can proceed to create an instance of TransformerHandler:
TransformerHandler transHand = saxTransFact.newTransformerHandler(myXsltSource);
This object now represents your XSLT stylesheet. As Figure 5-5 shows, TransformerHandler extends org.xml.sax.ContentHandler, so it knows how to listen to events from a SAX parser. The series of SAX events will provide the "fake XML" data, so the only remaining piece of the puzzle is to set the Result and tell the SAX parser to begin parsing. The TransformerHandler also provides a reference to a Transformer, which allows you to set output properties such as the character encoding, whether to indent the output or any other attributes of <xsl:output>.
Writing the actual SAX parser sounds harder than it really is. The process basically involves implementing the org.xml.sax.XMLReader interface, which provides numerous methods you can safely ignore for most applications. For example, when parsing a CSV file, it is probably not necessary to deal with namespaces or validation. The code for AbstractXMLReader.java is shown in Example 5-5. This is an abstract class that provides basic implementations of every method in the XMLReader interface except for the parse( ) method. This means that all you need to do to write a parser is create a subclass and override this single method.
package com.oreilly.javaxslt.util;
import java.io.IOException;
import java.util.*;
import org.xml.sax.*;
/**
* An abstract class that implements the SAX2 XMLReader interface. The
* intent of this class is to make it easy for subclasses to act as
* SAX2 XMLReader implementations. This makes it possible, for example, for
* them to emit SAX2 events that can be fed into an XSLT processor for
* transformation.
*/
public abstract class AbstractXMLReader implements org.xml.sax.XMLReader {
private Map featureMap = new HashMap( );
private Map propertyMap = new HashMap( );
private EntityResolver entityResolver;
private DTDHandler dtdHandler;
private ContentHandler contentHandler;
private ErrorHandler errorHandler;
/**
* The only abstract method in this class. Derived classes can parse
* any source of data and emit SAX2 events to the ContentHandler.
*/
public abstract void parse(InputSource input) throws IOException,
SAXException;
public boolean getFeature(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {
Boolean featureValue = (Boolean) this.featureMap.get(name);
return (featureValue == null) ? false
: featureValue.booleanValue( );
}
public void setFeature(String name, boolean value)
throws SAXNotRecognizedException, SAXNotSupportedException {
this.featureMap.put(name, new Boolean(value));
}
public Object getProperty(String name)
throws SAXNotRecognizedException, SAXNotSupportedException {
return this.propertyMap.get(name);
}
public void setProperty(String name, Object value)
throws SAXNotRecognizedException, SAXNotSupportedException {
this.propertyMap.put(name, value);
}
public void setEntityResolver(EntityResolver entityResolver) {
this.entityResolver = entityResolver;
}
public EntityResolver getEntityResolver( ) {
return this.entityResolver;
}
public void setDTDHandler(DTDHandler dtdHandler) {
this.dtdHandler = dtdHandler;
}
public DTDHandler getDTDHandler( ) {
return this.dtdHandler;
}
public void setContentHandler(ContentHandler contentHandler) {
this.contentHandler = contentHandler;
}
public ContentHandler getContentHandler( ) {
return this.contentHandler;
}
public void setErrorHandler(ErrorHandler errorHandler) {
this.errorHandler = errorHandler;
}
public ErrorHandler getErrorHandler( ) {
return this.errorHandler;
}
public void parse(String systemId) throws IOException, SAXException {
parse(new InputSource(systemId));
}
}Creating the subclass, CSVXMLReader, involves overriding the parse( ) method and actually scanning through the CSV file, emitting SAX events as elements in the file are encountered. While the SAX portion is very easy, parsing the CSV file is a little more challenging. To make this class as flexible as possible, it was designed to parse through any CSV file that a spreadsheet such as Microsoft Excel can export. For simple data, your CSV file might look like this:
Burke,Eric,M Burke,Jennifer,L Burke,Aidan,G
The XML representation of this file is shown in Example 5-6. The only real drawback here is that CSV files are strictly positional, meaning that names are not assigned to each column of data. This means that the XML output merely contains a sequence of three <value> elements for each line, so your stylesheet will have to select items based on position.
<?xml version="1.0" encoding="UTF-8"?>
<csvFile>
<line>
<value>Burke</value>
<value>Eric</value>
<value>M</value>
</line>
<line>
<value>Burke</value>
<value>Jennifer</value>
<value>L</value>
</line>
<line>
<value>Burke</value>
<value>Aidan</value>
<value>G</value>
</line>
</csvFile>One enhancement would be to design the CSV parser so it could accept a list of meaningful column names as parameters, and these could be used in the XML that is generated. Another option would be to write an XSLT stylesheet that transformed this initial output into another form of XML that used meaningful column names. To keep the code example relatively manageable, these features were omitted from this implementation. But there are some complexities to the CSV file format that have to be considered. For example, fields that contain commas must be surrounded with quotes:
"Consultant,Author,Teacher",Burke,Eric,M Teacher,Burke,Jennifer,L None,Burke,Aidan,G
To further complicate matters, fields may also contain quotes ("). In this case, they are doubled up, much in the same way you use double backslash characters (\\) in Java to represent a single backslash. In the following example, the first column contains a single quote, so the entire field is quoted, and the single quote is doubled up:
"test""quote",Teacher,Burke,Jennifer,L
This would be interpreted as:
test"quote,Teacher,Burke,Jennifer,L
The code in Example 5-7 shows the complete implementation of the CSV parser.
package com.oreilly.javaxslt.util;
import java.io.*;
import java.net.URL;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
/**
* A utility class that parses a Comma Separated Values (CSV) file
* and outputs its contents using SAX2 events. The format of CSV that
* this class reads is identical to the export format for Microsoft
* Excel. For simple values, the CSV file may look like this:
* <pre>
* a,b,c
* d,e,f
* </pre>
* Quotes are used as delimiters when the values contain commas:
* <pre>
* a,"b,c",d
* e,"f,g","h,i"
* </pre>
* And double quotes are used when the values contain quotes. This parser
* is smart enough to trim spaces around commas, as well.
*
* @author Eric M. Burke
*/
public class CSVXMLReader extends AbstractXMLReader {
// an empty attribute for use with SAX
private static final Attributes EMPTY_ATTR = new AttributesImpl( );
/**
* Parse a CSV file. SAX events are delivered to the ContentHandler
* that was registered via <code>setContentHandler</code>.
*
* @param input the comma separated values file to parse.
*/
public void parse(InputSource input) throws IOException,
SAXException {
// if no handler is registered to receive events, don't bother
// to parse the CSV file
ContentHandler ch = getContentHandler( );
if (ch == null) {
return;
}
// convert the InputSource into a BufferedReader
BufferedReader br = null;
if (input.getCharacterStream( ) != null) {
br = new BufferedReader(input.getCharacterStream( ));
} else if (input.getByteStream( ) != null) {
br = new BufferedReader(new InputStreamReader(
input.getByteStream( )));
} else if (input.getSystemId( ) != null) {
java.net.URL url = new URL(input.getSystemId( ));
br = new BufferedReader(new InputStreamReader(url.openStream( )));
} else {
throw new SAXException("Invalid InputSource object");
}
ch.startDocument( );
// emit <csvFile>
ch.startElement("","","csvFile",EMPTY_ATTR);
// read each line of the file until EOF is reached
String curLine = null;
while ((curLine = br.readLine( )) != null) {
curLine = curLine.trim( );
if (curLine.length( ) > 0) {
// create the <line> element
ch.startElement("","","line",EMPTY_ATTR);
// output data from this line
parseLine(curLine, ch);
// close the </line> element
ch.endElement("","","line");
}
}
// emit </csvFile>
ch.endElement("","","csvFile");
ch.endDocument( );
}
// Break an individual line into tokens. This is a recursive function
// that extracts the first token, then recursively parses the
// remainder of the line.
private void parseLine(String curLine, ContentHandler ch)
throws IOException, SAXException {
String firstToken = null;
String remainderOfLine = null;
int commaIndex = locateFirstDelimiter(curLine);
if (commaIndex > -1) {
firstToken = curLine.substring(0, commaIndex).trim( );
remainderOfLine = curLine.substring(commaIndex+1).trim( );
} else {
// no commas, so the entire line is the token
firstToken = curLine;
}
// remove redundant quotes
firstToken = cleanupQuotes(firstToken);
// emit the <value> element
ch.startElement("","","value",EMPTY_ATTR);
ch.characters(firstToken.toCharArray(), 0, firstToken.length( ));
ch.endElement("","","value");
// recursively process the remainder of the line
if (remainderOfLine != null) {
parseLine(remainderOfLine, ch);
}
}
// locate the position of the comma, taking into account that
// a quoted token may contain ignorable commas.
private int locateFirstDelimiter(String curLine) {
if (curLine.startsWith("\"")) {
boolean inQuote = true;
int numChars = curLine.length( );
for (int i=1; i<numChars; i++) {
char curChar = curLine.charAt(i);
if (curChar == '"') {
inQuote = !inQuote;
} else if (curChar == ',' && !inQuote) {
return i;
}
}
return -1;
} else {
return curLine.indexOf(',');
}
}
// remove quotes around a token, as well as pairs of quotes
// within a token.
private String cleanupQuotes(String token) {
StringBuffer buf = new StringBuffer( );
int length = token.length( );
int curIndex = 0;
if (token.startsWith("\"") && token.endsWith("\"")) {
curIndex = 1;
length--;
}
boolean oneQuoteFound = false;
boolean twoQuotesFound = false;
while (curIndex < length) {
char curChar = token.charAt(curIndex);
if (curChar == '"') {
twoQuotesFound = (oneQuoteFound) ? true : false;
oneQuoteFound = true;
} else {
oneQuoteFound = false;
twoQuotesFound = false;
}
if (twoQuotesFound) {
twoQuotesFound = false;
oneQuoteFound = false;
curIndex++;
continue;
}
buf.append(curChar);
curIndex++;
}
return buf.toString( );
}
}CSVXMLReader is a subclass of AbstractXMLReader, so it must provide an implementation of the abstract parse method:
public void parse(InputSource input) throws IOException,
SAXException {
// if no handler is registered to receive events, don't bother
// to parse the CSV file
ContentHandler ch = getContentHandler( );
if (ch == null) {
return;
}The first thing this method does is check for the existence of a SAX ContentHandler. The base class, AbstractXMLReader, provides access to this object, which is responsible for listening to the SAX events. In our example, an instance of JAXP's TransformerHandler is used as the SAX ContentHandler implementation. If this handler is not registered, our parse method simply returns because nobody is registered to listen to the events. In a real SAX parser, the XML would be parsed anyway, which provides an opportunity to check for errors in the XML data. Choosing to return immediately was merely a performance optimization selected for this class.
The SAX InputSource parameter allows our custom parser to locate the CSV file. Since an InputSource has many options for reading its data, parsers must check each potential source in the order shown here:
// convert the InputSource into a BufferedReader
BufferedReader br = null;
if (input.getCharacterStream( ) != null) {
br = new BufferedReader(input.getCharacterStream( ));
} else if (input.getByteStream( ) != null) {
br = new BufferedReader(new InputStreamReader(
input.getByteStream( )));
} else if (input.getSystemId( ) != null) {
java.net.URL url = new URL(input.getSystemId( ));
br = new BufferedReader(new InputStreamReader(url.openStream( )));
} else {
throw new SAXException("Invalid InputSource object");
}Assuming that our InputSource was valid, we can now begin parsing the CSV file and emitting SAX events. The first step is to notify the ContentHandler that a new document has begun:
ch.startDocument( );
// emit <csvFile>
ch.startElement("","","csvFile",EMPTY_ATTR);The XSLT processor interprets this to mean the following:
<?xml version="1.0" encoding="UTF-8"?> <csvFile>
Our parser simply ignores many SAX 2 features, particularly XML namespaces. This is why many values passed as parameters to the various ContentHandler methods simply contain empty strings. The EMPTY_ATTR constant indicates that this XML element does not have any attributes.
The CSV file itself is very straightforward, so we merely loop over every line in the file, emitting SAX events as we read each line. The parseLine method is a private helper method that does the actual CSV parsing:
// read each line of the file until EOF is reached
String curLine = null;
while ((curLine = br.readLine( )) != null) {
curLine = curLine.trim( );
if (curLine.length( ) > 0) {
// create the <line> element
ch.startElement("","","line",EMPTY_ATTR);
parseLine(curLine, ch);
ch.endElement("","","line");
}
}And finally, we must indicate that the parsing is complete:
// emit </csvFile>
ch.endElement("","","csvFile");
ch.endDocument( );The remaining methods in CSVXMLReader are not discussed in detail here because they are really just responsible for breaking down each line in the CSV file and checking for commas, quotes, and other mundane parsing tasks. One thing worth noting is the code that emits text, such as the following:
<value>Some Text Here</value>
SAX parsers use the characters method on ContentHandler to represent text, which has this signature:
public void characters(char[] ch, int start, int length)
Although this method could have been designed to take a String, using an array allows SAX parsers to preallocate a large character array and then reuse that buffer repeatedly. This is why an implementation of ContentHandler cannot simply assume that the entire ch array contains meaningful data. Instead, it must read only the specified number of characters beginning at the start position.
Our parser uses a relatively straightforward approach, simply converting a String to a character array and passing that as a parameter to the characters method:
// emit the <value>text</value> element
ch.startElement("","","value",EMPTY_ATTR);
ch.characters(firstToken.toCharArray(), 0, firstToken.length( ));
ch.endElement("","","value");To wrap things up, let's look at how you will actually use this CSV parser with an XSLT stylesheet. The code shown in Example 5-8 is a standalone Java application that allows you to perform XSLT transformations on CSV files. As the comments indicate, it requires the name of a CSV file as its first parameter and can optionally take the name of an XSLT stylesheet as its second parameter. All output is sent to System.out.
package com.oreilly.javaxslt.util;
import java.io.*;
import javax.xml.transform.*;
import javax.xml.transform.sax.*;
import javax.xml.transform.stream.*;
import org.xml.sax.*;
/**
* Shows how to use the CSVXMLReader class. This is a command-line
* utility that takes a CSV file and optionally an XSLT file as
* command line parameters. A transformation is applied and the
* output is sent to System.out.
*/
public class SimpleCSVProcessor {
public static void main(String[] args) throws Exception {
if (args.length == 0) {
System.err.println("Usage: java "
+ SimpleCSVProcessor.class.getName( )
+ " <csvFile> [xsltFile]");
System.err.println(" - csvFile is required");
System.err.println(" - xsltFile is optional");
System.exit(1);
}
String csvFileName = args[0];
String xsltFileName = (args.length > 1) ? args[1] : null;
TransformerFactory transFact = TransformerFactory.newInstance( );
if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {
SAXTransformerFactory saxTransFact =
(SAXTransformerFactory) transFact;
TransformerHandler transHand = null;
if (xsltFileName == null) {
transHand = saxTransFact.newTransformerHandler( );
} else {
transHand = saxTransFact.newTransformerHandler(
new StreamSource(new File(xsltFileName)));
}
// set the destination for the XSLT transformation
transHand.setResult(new StreamResult(System.out));
// hook the CSVXMLReader to the CSV file
CSVXMLReader csvReader = new CSVXMLReader( );
InputSource csvInputSrc = new InputSource(
new FileReader(csvFileName));
// attach the XSLT processor to the CSVXMLReader
csvReader.setContentHandler(transHand);
csvReader.parse(csvInputSrc);
} else {
System.err.println("SAXTransformerFactory is not supported.");
System.exit(1);
}
}
}As mentioned earlier in this chapter, the TransformerHandler is provided by JAXP and is an implementation of the org.xml.sax.ContentHandler interface. It is constructed by the SAXTransformerFactory as follows:
TransformerHandler transHand = null;
if (xsltFileName == null) {
transHand = saxTransFact.newTransformerHandler( );
} else {
transHand = saxTransFact.newTransformerHandler(
new StreamSource(new File(xsltFileName)));
}When the XSLT stylesheet is not specified, the transformer performs an identity transformation. This is useful when you just want to see the raw XML output without applying a stylesheet. You will probably want to do this first to see how your XSLT will need to be written. If a stylesheet is provided, however, it is used for the transformation.
The custom parser is then constructed as follows:
CSVXMLReader csvReader = new CSVXMLReader( );
The location of the CSV file is then converted into a SAX InputSource:
InputSource csvInputSrc = new InputSource(
new FileReader(csvFileName));And finally, the XSLT processor is attached to our custom parser. This is accomplished by registering the TransformerHandler as the ContentHandler on csvReader. A single call to the parse method causes the parsing and transformation to occur:
// attach the XSLT processor to the CSVXMLReader csvReader.setContentHandler(transHand); csvReader.parse(csvInputSrc);
For a simple test, assume that a list of presidents is available in CSV format:
Washington,George,, Adams,John,, Jefferson,Thomas,, Madison,James,, etc... Bush,George,Herbert,Walker Clinton,William,Jefferson, Bush,George,W,
To see what the XML looks like, invoke the program as follows:
java com.oreilly.javaxslt.util.SimpleCSVProcessor presidents.csv
This will parse the CSV file and apply the identity transformation stylesheet, sending the following output to the console:
<?xml version="1.0" encoding="UTF-8"?>
<csvFile>
<line>
<value>Washington</value>
<value>George</value>
<value/>
<value/>
</line>
<line>
etc...
</csvFile>Actually, the output is crammed onto a single long line, but it is broken up here to make it more readable. Any good XML editor application should provide a feature to pretty-print the XML as shown. In order to transform this into something useful, a stylesheet is required. The XSLT stylesheet shown in Example 5-9 takes any output from this program and converts it into an HTML table.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<table border="1">
<xsl:apply-templates select="csvFile/line"/>
</table>
</xsl:template>
<xsl:template match="line">
<tr>
<xsl:apply-templates select="value"/>
</tr>
</xsl:template>
<xsl:template match="value">
<td>
<!-- If a value is empty, print a non-breaking space
so the HTML table looks OK -->
<xsl:if test=".=''">
<xsl:text> disable-output-escaping="yes">&nbsp;</xsl:text>
</xsl:if>
<xsl:value-of select="."/>
</td>
</xsl:template>
</xsl:stylesheet>In order to apply this stylesheet, type the following command:
java com.oreilly.javaxslt.util.SimpleCSVProcessor presidents.csv csvToHTMLTable.xslt
As before, the results are sent to System.out and contain code for an HTML table. This stylesheet will work with any CSV file parsed with SimpleCSVProcessor, not just presidents.xml. Now that the concept has been proved, you can add fancy formatting and custom output to the resulting HTML without altering any Java code -- just edit the stylesheet or write a new one.
Although writing a SAX parser and connecting it to JAXP does involve quite a few interrelated classes, the resulting application requires only two command-line arguments and will work with any CSV or XSLT file. What makes this example interesting is that the same approach will work with essentially any data source. The steps are broken down as follows:
Create a custom SAX parser by implementing org.xml.sax.XMLReader or extending com.oreilly.javaxslt.util.AbstractXMLReader.
In your parser, emit the appropriate SAX events as you read your data.
Modify SimpleCSVProcessor to utilize your custom parser instead of CSVXMLReader.
For example, you might want to write a custom parser that accepts a SQL statement as input rather than a CSV file. Your parser could then connect to a database, issue the query, and fire SAX events for each row in the ResultSet. This makes it very easy to extract data from any relational database without writing a lot of custom code. This also eliminates the intermediate step of JDOM or DOM production because the SAX events are fed directly into JAXP for transformation.
The DOM API is tedious to use, so many Java programmers opt for JDOM instead. The typical usage pattern is to generate XML dynamically using JDOM and then somehow transform that into a web page using XSLT. This presents a problem because JAXP does not provide any direct implementation of the javax.xml.Source interface that integrates with JDOM.[22] There are at least three available options:
[22] As this is being written, members of the JDOM community are writing a JDOM implementation of javax.xml.Source that will directly integrate with JAXP.
Use org.jdom.output.SAXOutputter to pipe SAX 2 events from JDOM to JAXP.
Use org.jdom.output.DOMOutputter to convert the JDOM tree to a DOM tree, and then use javax.xml.transform.dom.DOMSource to read the data into JAXP.
Use org.jdom.output.XMLOutputter to serialize the JDOM tree to XML text, and then use java.xml.transform.stream.StreamSource to parse the XML back into JAXP.
The SAX approach is generally preferable to other approaches. Its primary advantage is that it does not require an intermediate transformation to convert the JDOM tree into a DOM tree or text. This offers the lowest memory utilization and potentially the fastest performance.
In support of SAX, JDOM offers the org.jdom.output.SAXOutputter class. The following code fragment demonstrates its usage:
TransformerFactory transFact = TransformerFactory.newInstance( );
if (transFact.getFeature(SAXTransformerFactory.FEATURE)) {
SAXTransformerFactory stf = (SAXTransformerFactory) transFact;
// the 'stylesheet' parameter is an instance of JAXP's
// javax.xml.transform.Templates interface
TransformerHandler transHand = stf.newTransformerHandler(stylesheet);
// result is a Result instance
transHand.setResult(result);
SAXOutputter saxOut = new SAXOutputter(transHand);
// the 'jdomDoc' parameter is an instance of JDOM's
// org.jdom.Document class. In contains the XML data
saxOut.output(jdomDoc);
} else {
System.err.println("SAXTransformerFactory is not supported");
}The DOM approach is generally a little slower and will not work if JDOM uses a different DOM implementation than JAXP. JDOM, like JAXP, can utilize different DOM implementations behind the scenes. If JDOM refers to a different version of DOM than JAXP, you will encounter exceptions when you try to perform the transformation. Since JAXP uses Apache's Crimson parser by default, you can configure JDOM to use Crimson with the org.jdom.adapters.CrimsonDOMAdapter class. The following code shows how to convert a JDOM Document into a DOM Document:
org.jdom.Document jdomDoc = createJDOMDocument( );
// add data to the JDOM Document
...
// convert the JDOM Document into a DOM Document
org.jdom.output.DOMOutputter domOut = new org.jdom.output.DOMOutputter(
"org.jdom.adapters.CrimsonDOMAdapter");
org.w3c.dom.Document domDoc = domOut.output(jdomDoc);The second line is highlighted because it is likely to give you the most problems. When JDOM converts its internal object tree into a DOM object tree, it must use some underlying DOM implementation. In many respects, JDOM is similar to JAXP because it delegates many tasks to underlying implementation classes. The DOMOutputter constructors are overloaded as follows:
// use the default adapter class public DOMOutputter( ) // use the specified adapter class public DOMOutputter(String adapterClass)
The first constructor shown here will use JDOM's default DOM parser, which is not necessarily the same DOM parser that JAXP uses. The second method allows you to specify the name of an adapter class, which must implement the org.jdom.adapters.DOMAdapter interface. JDOM includes standard adapters for all of the widely used DOM implementations, or you could write your own adapter class.
In the final approach listed earlier, you can utilize java.io.StringWriter and java.io.StringReader. First create the JDOM data as usual, then use org.jdom.output.XMLOutputter to convert the data into a String of XML:
StringWriter sw = new StringWriter( );
org.jdom.output.XMLOutputter xmlOut
= new org.jdom.output.XMLOutputter("", false);
xmlOut.output(jdomDoc, sw);The parameters for XMLOutputter allow you to specify the amount of indentation for the output along with a boolean flag indicating whether or not linefeeds should be included in the output. In the code example, no spaces or linefeeds are specified in order to minimize the size of the XML that is produced. Now that the StringWriter contains your XML, you can use a StringReader along with javax.xml.transform.stream.StreamSource to read the data into JAXP:
StringReader sr = new StringReader(sw.toString( )); Source xmlSource = new javax.xml.transform.stream.StreamSource(sr);
The transformation can then proceed just as it did in Example 5-4. The main drawback to this approach is that the XML, once converted to text form, must then be parsed back in by JAXP before the transformation can be applied.
|  | |
| 5.2. Introduction to JAXP 1.1 |  | 5.4. Stylesheet Compilation |

Copyright © 2002 O'Reilly & Associates. All rights reserved.