|  |

| |
The Node interface is the DOM Core class hierarchy's root. Though never instantiated directly, it is the root interface of all specific interfaces, and you can use it to extract information from any DOM object without knowing its actual type. It is possible to access a document's complete structure and content using only the methods and properties exposed by the Node interface. As shown in Table 18-1, this interface contains information about the type, location, name, and value of the corresponding underlying document data.
|
Type |
Name |
Read-only |
DOM 2.0 |
|
|---|---|---|---|---|
|
Attributes |
||||
|
DOMString |
nodeName |
|
||
|
DOMString |
nodeValue |
|||
|
Short |
Unsigned type |
|
||
|
Node |
parentNode |
|
||
|
NodeList |
childNodes |
|
||
|
Node |
firstChild |
|
||
|
Node |
lastChild |
|
||
|
Node |
previousSibling |
|
||
|
Node |
nextSibling |
|
||
|
NamedNodeMap |
attributes |
|
||
|
Document |
ownerDocument |
|
|
|
|
DOMString |
namespaceURI |
|
|
|
|
DOMString |
Prefix |
|
||
|
DOMString |
localName |
|
|
|
|
Methods |
||||
|
Boolean |
hasAttributes |
|
||
|
Node |
insertBefore |
|||
|
Node |
newChild |
|||
|
Node |
refChild |
|||
|
Node |
replaceChild |
|||
|
Node |
newChild |
|||
|
Node |
oldChild |
|||
|
Node |
removeChild |
|||
|
Node |
oldChild |
|||
|
Node |
appendChild |
|||
|
Node |
newChild |
|||
|
Boolean |
hasChildNodes |
|||
|
Node |
cloneNode |
|||
|
Boolean |
Deep |
|||
|
Void |
normalize |
|
||
|
Boolean |
isSupported |
|
||
|
DOMString |
Feature |
|
||
|
DOMString |
Version |
|
Since the Node interface is never instantiated directly, the nodeType attribute contains a value that indicates the given instance's specific object type. Based on the nodeType, it is possible to cast a generic Node reference safely to a specific interface for further processing. Table 18-2 shows the node type values and their corresponding DOM interfaces, and Table 18-3 shows the values they provide for nodeName, nodeValue, and attributes attributes.
|
Node type |
DOM interface |
|---|---|
|
Attr |
|
|
CDATASection |
|
|
Comment |
|
|
DocumentFragment |
|
|
Document |
|
|
DocumentType |
|
|
Element |
|
|
Entity |
|
|
EntityReference |
|
|
Notation |
|
|
ProcessingInstruction |
|
|
Text |
|
Node type |
nodeName |
nodeValue |
Attributes |
|---|---|---|---|
|
ATTRIBUTE_NODE |
att name |
att value |
null |
|
CDATA_SECTION_NODE |
#cdata-section |
content |
null |
|
COMMENT_NODE |
#comment |
content |
null |
|
DOCUMENT_FRAGMENT_NODE |
#document-fragment |
null |
null |
|
DOCUMENT_NODE |
#document |
null |
null |
|
DOCUMENT_TYPE_NODE |
document type name |
null |
null |
|
ELEMENT_NODE |
tag name |
null |
NamedNodeMap |
|
ENTITY_NODE |
entity name |
null |
null |
|
ENTITY_REFERENCE_NODE |
name of entity referenced |
null |
null |
|
NOTATION_NODE |
notation name |
null |
null |
|
PROCESSING_INSTRUCTION_NODE |
target |
content excluding the target |
null |
|
TEXT_NODE |
#text |
content |
null |
Note that the nodeValue attribute returns the contents of simple text and comment nodes, but returns nothing for elements. Retrieving the text of an element requires inspecting the text nodes it contains.
The NodeList interface provides access to the ordered content of a node. Most frequently, it is used to retrieve text nodes and child elements of element nodes. See Table 18-4 for a summary of the NodeList interface.
|
Type |
Name |
Read-only |
DOM 2.0 |
|
|---|---|---|---|---|
|
Attributes |
||||
|
Long |
length |
|
||
|
Methods |
||||
|
Node |
item |
|||
|
Long |
index |
The NodeList interface is extremely basic and is generally combined with a loop to iterate over the children of a node.
The NamedNodeMap interface is used for unordered collections whose contents are identified by name. In practice, this interface is used to access attributes. See Table 18-5 for a summary of the NamedNodeMap interface.
|
Type |
Name |
Read-only |
DOM 2.0 |
|
|---|---|---|---|---|
|
Attributes |
||||
|
Long |
length |
|
||
|
Methods |
||||
|
Node |
getNamedItem |
|||
|
DOMString |
name |
|||
|
Node |
setNamedItem |
|||
|
Node |
arg |
|||
|
Node |
removeNamedItem |
|||
|
DOMString |
name |
|||
|
Node |
getNamedItemNS |
|
||
|
DOMString |
namespaceURI |
|
||
|
DOMString |
localName |
|
||
|
Node |
setNamedItemNS |
|
||
|
Node |
arg |
|
||
|
Node |
removeNamedItemNS |
|||
|
DOMString |
namespaceURI |
|
||
|
DOMString |
localName |
|
Although the DOM doesn't specify an interface to cause a document to be parsed, it does specify how the document's syntax structures are encoded as DOM objects. A document is stored as a hierarchical tree structure, with each item in the tree linked to its parent, children, and siblings:
<sample bogus="value"><text_node>Test data.</text_node></sample>
Figure 18-1 shows how the preceding short sample document would be stored by a DOM parser.
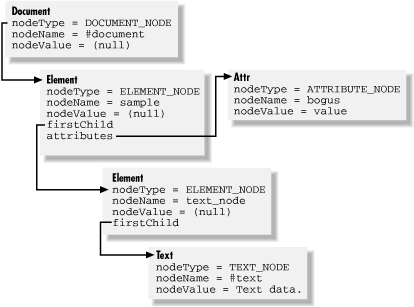
Each Node-derived object in a parsed DOM document contains references to its parent, child, and sibling nodes. These references make it possible for applications to enumerate document data using any number of standard tree-traversal algorithms. "Walking the tree" is a common approach to finding information stored in a DOM and is demonstrated in Example 18-1 at the end of this chapter.
|  | |
| 18.2. Structure of the DOM Core |  | 18.4. Specific Node-Type Interfaces |

Copyright © 2002 O'Reilly & Associates. All rights reserved.