 |  |

| |
By default, an XML parser assumes that XML documents are written in the UTF-8 encoding of Unicode. However, documents may instead be written in any character set the XML processor understands, provided that there's either some external metadata like an HTTP header or internal metadata like a byte order mark or an encoding declaration that specifies the character set. For example, a document written in the Latin-5 character set would need this XML declaration:
<?xml version="1.0" encoding="ISO-8859-9"?>
Most good XML processors understand many common character sets. The XML specification recommends the character names shown in Table 26-1. When using any of these character sets, you should use these names. Of these character sets, only UTF-8 and UTF-16 must be supported by all XML processors, though many XML processors support all character sets listed here, and many support additional character sets besides. When using character sets not listed here, you should use the names specified in the IANA character sets registry at http://www.iana.org/assignments/character-sets.
The XML 1.0 specification divides Unicode into five overlapping sets:
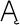 ,
, 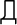 ,
,
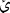 , 1, 2, 3,
, 1, 2, 3,  ,
, 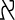 , and _.
, ,, , , and _. Because name start characters are a subset of name characters, they are also shown in bold.
, and _.
, ,, , , and _. Because name start characters are a subset of name characters, they are also shown in bold.
Figure 26-1 shows the relationship between these sets. Note that all name start characters are name characters and that all name characters are character data characters.
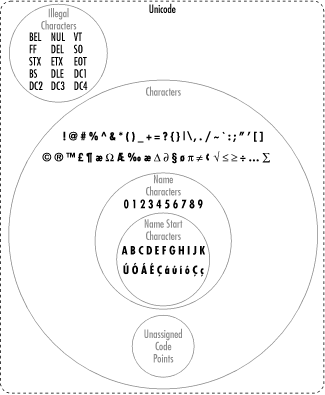
In all the tables that follow, each cell's upper lefthand corner contains the character's two-digit Unicode hexadecimal value and the upper righthand corner contains the character's Unicode decimal value. You can insert a character in an XML document by prefixing the decimal value with &# and suffixing it with a semicolon. Thus, Unicode character 69, the capital letter E, can be written as E. Hexadecimal values work the same way, except that you prefix them with &#x;. In hexadecimal, the letter E is 45, so it can also be written as E.
Most character sets in common use today are supersets of ASCII. That is, code points 0 through 127 are assigned to the same characters to which ASCII assigns them. Figure 26-2 lists the ASCII character set. The only notable exceptions are the EBCDIC-derived character sets. Specifically, Unicode is a superset of ASCII, and code points 1 through 127 identify the same characters in Unicode as they do in ASCII.
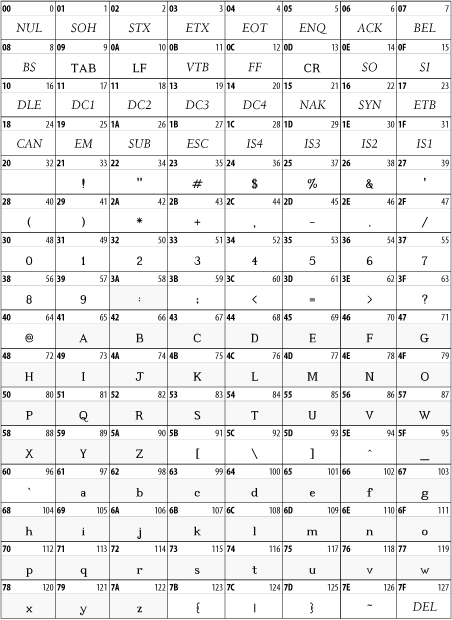
Characters 0 through 31 and character 127 are nonprinting control characters, sometimes called the C0 controls to distinguish them from the C1 controls used in the ISO-8859 character sets. Of these 33 characters, only the carriage return, linefeed, and horizontal tab may appear in XML documents. The other 29 may not appear anywhere in an XML document, including in tags, comments, or parsed character data. They may not be inserted with character references, such as . For example, you may not use form feeds to insert page breaks.
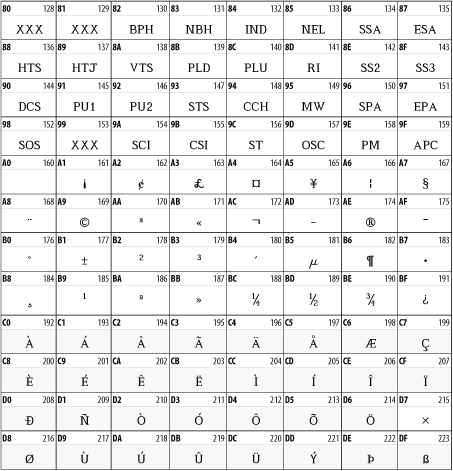
Character sets defined by the ISO-8859 standard comprise one popular superset of the ASCII character sets. These characters all provide the normal ASCII characters from code points 0 through 127 and the C1 controls from 128 to 159, as well as change the characters from 160 through 255.
In particular, many Western European and American systems use a character set called Latin-1. This set is the first code page defined in the ISO-8859 standard and is also called ISO-8859-1. Though all common encodings of Unicode map code points 128 through 255 differently than Latin-1, code points 128 through 255 map to the same characters in both Latin-1 and Unicode. This situation does not occur in other character sets.
All ISO-8859 character sets begin with the same 32 extra nonprinting control characters in code points 128 through 159. These sets are used on terminals like the DEC VT-320 to provide graphics functionality not included in ASCII, for example, erasing the screen and switching it to inverse video or graphics mode. These characters cause severe problems for anyone reading or editing an XML document on a terminal or terminal emulator.
Fortunately, these characters are not necessary in XML documents. Their inclusion in XML 1.0 was an oversight. They should have been banned like the C0 controls. Unfortunately, many editors and documents incorrectly label documents written in the Cp1252 Windows character set as ISO-8859-1. This character set does use the code points between 128 and 159 for noncontrol graphics characters. When documents written with this character set are displayed or edited on a dumb terminal, they can effectively disable the user's terminal. Similar problems exist with most other Windows code pages for single-byte character sets.
In the spirit of being liberal in what you accept and conservative in what you generate, you should never use Cp1252, correctly labeled or otherwise. You should also avoid using other nonstandard code pages for documents that move beyond a single system. On the other hand, if you receive a document labeled as Cp1252 (or any other Windows code page), it can be displayed if you're careful not to throw it at a terminal unchanged. If you suspect that a document labeled as ISO-8859-1 that uses characters between 128 and 159 is in fact a Cp1252 document, you should probably reject it. This decision is difficult, however, given the prevalence of broken software that does not identify documents sent properly.
Latin-1 covers most Western European languages
that use some variant of the Latin alphabet. Characters 0 through 127
in this set are identical to the ASCII characters with the same code
points. Characters 128 to 159 are the C1 control characters used only
for dumb terminals. Character 160 is the nonbreaking space.
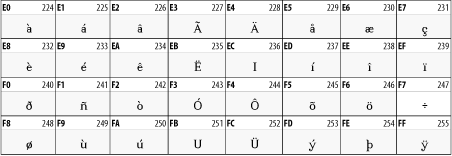
Characters 161 through 255 are accented characters, such as
è, á, and ö, non-U.S. punctuation
marks, such as £ and ¿, and a few new letters,
such as the Icelandic  and ß. Figure 26-3 shows the upper half of this character set. The lower half is identical to the ASCII character set shown in Figure 26-2.
and ß. Figure 26-3 shows the upper half of this character set. The lower half is identical to the ASCII character set shown in Figure 26-2.
|  | |
| 25.4. The org.xml.sax.ext Package |  | 26.2. HTML4 Entity Sets |

Copyright © 2002 O'Reilly & Associates. All rights reserved.
 ,
1,
,
1, 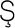 ,
,  ,
,
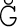 , and
, and  replace the less-commonly used
Icelandic
letters
replace the less-commonly used
Icelandic
letters  ,
, 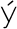 ,
,  ,
,
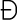 , and
, and 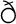 .
.
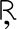 adds a few extra letters needed for Inuit and Lappish, and moves
various characters around. ISO-8859-13 now supersedes this character
set.
adds a few extra letters needed for Inuit and Lappish, and moves
various characters around. ISO-8859-13 now supersedes this character
set.
 ,
,  , and
, and 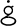 . These letters mostly replace
punctuation marks, such as x and |.
. These letters mostly replace
punctuation marks, such as x and |.
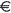 . It also
replaces the seldom-used fraction characters
1/4,
1/2,
and 3/4 with the
uncommon French letters ,
. It also
replaces the seldom-used fraction characters
1/4,
1/2,
and 3/4 with the
uncommon French letters , 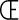 ,
, 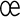 ,
,  and
the ¬,
and
the ¬,  , and ′ symbols with
the Finnish letters
, and ′ symbols with
the Finnish letters 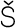 ,
, 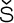 , and
, and 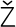 . Otherwise, it's
identical to ISO-8859-1.
. Otherwise, it's
identical to ISO-8859-1.