 |  |
| |
Set aside all the wisecracks about Perl being unmaintainable or useful only for small scripts. Also be prepared to renounce the widely held assumption that it's not a truly object-oriented language. In this section we will develop a general Perl framework that will let you quickly add new features to applications and adapt applications to changing database structures.
The code that follows is complex and requires an in-depth knowledge of Perl. Among the features of Perl we exploit are references, recursion, variable type checking, function argument manipulation (the $_[0] syntax), dynamic array building through push statements, and multidimensional hashes—and of course, lots of object-oriented techniques. These features are amply explained in other Perl books, notably Programming Perl by Larry Wall, Tom Christiansen, and Jon Orwant (O'Reilly).
Because the topic of this book is database interaction, the rest of this chapter focuses on the Model layer of the MVC methodology. We will show you how to design abstract methods that can be used and reused in a variety of applications. We'll also show how to weave persistence into your Model with minimal duplication of code, and—for good measure—speed up access by implementation a caching layer.
The Model contains abstractions of all concrete things used within the application. Therefore, a solid Model is an important foundation for the rest of the application.
Luckily for us, designing a Model for a database-driven application is straightforward. That is because the work of discovering the relevant abstractions in a system is done when the database scheme is created, as we described in Chapter 7.
Usually, each table in the database corresponds to one class in the Model. The fields of the tables correspond to the attributes of the class. Relationships between tables can usually be expressed in the following manner:
Like all classes, a Model class is comprised of attributes and methods. An attribute is simply a variable that describes something about the class. As mentioned above, the attributes of a Model class represent the fields of the underlying table and objects from related tables. But what about the methods?
In object-oriented programming, classes have two kinds of methods: instance and static. Instance methods are only called on actual objects created from the class. Because of this, they have access to the attribute data within the object. Static methods (also known as class methods) are called on the class itself. They have no knowledge of individual objects of that class. For instance, in the first section of this chapter, we saw a static DBI method called connect( ).
Persistence requires each Model class to implement three instance methods, which we'll call update, remove, and create. These methods parallel the SQL UPDATE, DELETE, and INSERT statements that, along with SELECT, make up the vast majority of SQL statements.
While these methods are the only required ones for a Model class, a common object-oriented practice is to use accessor or getter/setter methods to retrieve and change the values of attributes. If you do this, each attribute of the object should have two instance methods: a get method that retrieves the value of the attribute and a set method that sets the attribute to a new value. They can be named anything, but a common practice is to simply prepend "get" and "set" to the name of the attribute. So an attribute called firstName would have the methods getFirstName and setFirstName.
The instance methods described above cover three of the four basic SQL commands. This leaves SELECT unimplemented. To implement it, we turn to static methods. Unlike the others, the SELECT command does not operate on existing objects. The point of a SELECT query is to retrieve data from the database. In an object-oriented application, you must create new objects to represent data selected from the database. Therefore, it is necessary to use static methods that do not rely on instance data.
Therefore, we'll write a static method that sends SELECT queries to a database and creates new Model objects from the data returned. Unlike the other methods considered so far, there are often several methods within a Model class that need to select data. This is because there are usually different contexts in which to create new objects. We'll implement the two methods that almost every application needs: Generic Where and Primary Key. For better reuse of code, we'll implement Primary Key in terms of Generic Where. Only the latter needs to issue SQL.
You might consider Primary Key to be a utility or convenience function built on top of Generic Where.
In the rest of this chapter, we'll lay out the code that implements a robust Model for a class we'll call Publisher. For the sake of simplicity, each publisher has just two attributes: an ID and a name. The id field is the primary key and uniquely identifies each row of the table. The Name field is the name of the publisher.
In this class, you will recognize all the methods we discussed in the previous section. Of the 13 methods, 4 correspond directly to SQL activities:
Some of these calls invoke lower-level functions to handle SQL WHERE clauses. These WHERE clauses can be very complex, especially when multiple tables are involved. Clauses may even be nested. The information stored within an SQL WHERE clause can also be stored in a Perl multilevel hash without losing any information. We allow a WHERE clause of any complexity by encapsulating the processing of the clause in the following two functions:
The following functions get and set the two attributes:
The following is the Primary Key select function described in the previous section:
The following are constructors:
This Publisher.pm module must be located in a directory we've called CBDB. In addition to this class, which you can generalize and apply to other applications, we use three helper classes. These are entirely generic and can be reused in any application empoying our Model.
If you like to learn code from the bottom up, read the sections on the helper classes, then return to read the code for the Publisher class.
Finally, you may understand the wealth of functions better by seeing them organized into a hierarchy and seeing which functions are called by others. Figure 9-1 shows the main ways functions are called during major database operations.
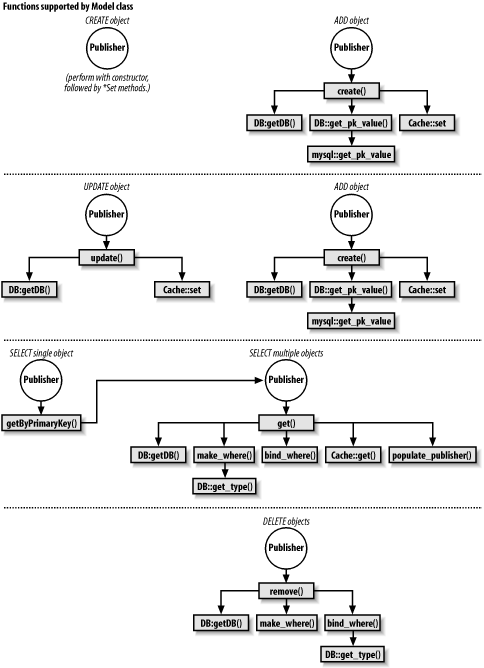
In the following subsections, we'll introduce each method of this class in the order in which we've previously described it. The file begins with the following initializations.
package CBDB::Publisher; our $VERSION = '1.0'; use strict; use DBI qw(:sql_types); use CBDB::DB; use CBDB::Cache; our @ISA = qw( CBDB::DB );
The create( ), get( ), remove( ), and update( ) methods are fairly short and simple. They check the types of their input arguments, build SQL queries or updates in the ways shown earlier in this chapter, and execute the SQL. They also interact with the cache. Example 9-6 demonstrates this.
#################################################
# create() - Inserts the object into the database.
# Parameters: None.
# Returns: A Publisher object (redundantly, because
# this method is called on that same object).
sub create {
my $self = shift;
my $dbh = CBDB::DB::getDB( );
my $query = "INSERT INTO publisher ( name, id ) VALUES ( ?, ? )";
my $sth = $dbh->prepare($query);
my $pk_id = undef;
$sth->bind_param(1, $self->getName( ), {TYPE=>1});
$sth->bind_param(2, undef, {TYPE=>4});
$sth->execute;
$sth->finish;
$pk_id = CBDB::DB::get_pk_value($dbh, 'publisher_id');
$self->setId( $pk_id);
$dbh->disconnect;
CBDB::Cache::set('publisher', $self->getId( ), $self);
return $self;
}
#################################################
# get() - Retrieves objects from the database.
# Parameters: Optional WHERE clause.
# Returns: Array of Publisher objects.
sub get {
my $wheres = undef;
my $do_all = 1;
if (ref($_[0]) eq 'ARRAY') { $wheres = shift; $do_all = shift if @_; }
else { $do_all = shift; }
my $dbh = CBDB::DB::getDB( );
my $where .= ' WHERE ' . make_where( $wheres );
my $query = qq{
SELECT publisher.name as publisher_name,
publisher.id as publisher_id
FROM publisher
$where
};
my $sth = $dbh->prepare($query);
bind_where( $sth, $wheres );
$sth->execute;
my @publishers;
while (my $Ref = $sth->fetchrow_hashref) {
my $publisher = undef;
if (CBDB::Cache::has('publisher', $Ref->{publisher_id})) {
$publisher = CBDB::Cache::get('publisher', $Ref->{publisher_id});
} else {
$publisher = CBDB::Publisher::populate_publisher( $Ref );
CBDB::Cache::set('publisher',
$Ref->{publisher_id}, $publisher);
}
push(@publishers, $publisher);
}
$sth->finish;
$dbh->disconnect;
return @publishers;
}
#################################################
# remove( ) - Removes an object from the database.
# This method can be called on an object to delete
# that object, or statically, with a WHERE clause,
# to delete multiple objects.
# Parameters: An optional where clause.
# Returns: Nothing.
sub remove {
my $self = undef;
my $where = undef;
my $is_static = undef;
if ( ref($_[0]) and $_[0]->isa("CBDB::Publisher") ) {
$self = shift;
$where = "WHERE id = ?";
} elsif (ref($_[0]) eq 'HASH') {
$is_static = 1;
$where = 'WHERE ' . make_where($_[0]);
} else {
die "CBDB::Publisher::remove: Unknown parameters: " . join(' ', @_);
}
my $dbh = CBDB::DB::getDB( );
my $query = "DELETE FROM publisher $where";
my $sth = $dbh->prepare($query);
if ($is_static) {
bind_where($sth, $_[0]);
} else {
$sth->bind_param(1, $self->getId( ), {TYPE=>4});
}
$sth->execute;
$sth->finish;
$dbh->disconnect;
}
#################################################
# update( ) - Updates this object in the database.
# Parameters: None.
# Returns: Nothing.
sub update {
my $self = shift;
my $dbh = CBDB::DB::getDB( );
my $query = "UPDATE publisher SET name = ?, id = ? WHERE id = ?";
my $sth = $dbh->prepare($query);
$sth->bind_param(1, $self->getName( ), {TYPE=>1});
$sth->bind_param(2, $self->getId( ), {TYPE=>4});
$sth->bind_param(3, $self->getId( ), {TYPE=>4});
$sth->execute;
$sth->finish;
$dbh->disconnect;
CBDB::Cache::set('publisher', $self->getId( ), $self);
}
The make_where() and bind_where( ) methods are the most complex in our Model, because they must unpack and process complex data structures: Perl hashes, sometimes containing nested hashes. The make_where( ) method takes the Perl hash as input and converts its contents to a string containing a valid WHERE clause. The bind_where( ) method is even more complicated. It takes a statement handle and an array (sometimes containing nested arrays) of bind variables. It issues bind_param( ) calls to bind values to the proper places in the statement handle.
The WHERE clause used by the get and remove methods is in the form of a array reference. Each element of the array is either a single WHERE element or a reference to another array. If it is a reference to another array, the elements in that array are recursively embedded into the WHERE clause to allow clauses such as:
element AND (element OR (element AND element))
A single WHERE element is a hash reference that has at least the keys column and value. These contain the column name and value of the WHERE element. Other optional keys include type, which is the SQL operator used to join this element with the next element (it defaults to AND) and operator, which is the SQL operator used between the column name and the value (it defaults to an equals sign). Example 9-7 shows methods that handle WHERE clauses.
#################################################
# make_where( ) - Construct a WHERE clause from a well-defined hash ref.
# Parameters: WHERE clause reference.
# Returns: WHERE clause string.
sub make_where {
my $where_ref = shift;
if ( ref($where_ref) ne 'ARRAY' ) {
die "CBDB::Publisher::make_where: Unknown parameters: " .
join(' ', @_);
}
my @wheres = @$where_ref;
my $element_counter = 0;
my $where = "";
for my $element_ref (@wheres) {
if (ref($element_ref) eq 'ARRAY') {
$where .= make_where($element_ref);
} elsif (ref($element_ref) ne 'HASH') {
die "CBDB::Publisher::make_where: malformed WHERE parameter: "
. $element_ref;
}
my %element = %$element_ref;
my $type = 'AND';
if (not $element_counter and scalar keys %element == 1 and
exists($element{'TYPE'})) {
$type = $element{'TYPE'};
} else {
my $table = "publisher";
my $operator = "=";
if (exists($element{'table'})) { $table = $element{'table'}; }
if (exists($element{'operator'}))
{ $operator = $element{'operator'}; }
if ($element_counter) { $where .= " $type "; } else
{ $element_counter = 1; }
for my $term ( grep !/^(table|operator)$/, keys %element ) {
$where .= "$table.$term $operator ?";
}
}
}
return $where;
}
#################################################
# bind_where( ) - Executes the handle->bind method that binds the
# where element.
# Parameters: WHERE clause array ref and a scalar
# ref to a counter number that tells the method
# which parameter to bind to.
# Returns: Nothing.
sub bind_where {
my $sth = shift;
my $where_ref = shift;
my $counter_ref = shift || undef;
my $counter = (ref($counter_ref) eq 'Scalar')? $$counter_ref : 1;
if ( not $sth->isa('DBI::st') or ref($where_ref) ne 'ARRAY' ) {
die "CBDB::Publisher::make_where: Unknown parameters: "
. join(' ', @_);
}
my @wheres = @$where_ref;
for my $element_ref (@wheres) {
if (ref($element_ref) eq 'ARRAY') {
bind_where($sth, $element_ref, \$counter);
} elsif (ref($element_ref) ne 'HASH') {
die "CBDB::Publisher::make_where: malformed WHERE parameter: "
. $_;
}
my %element = %$element_ref;
unless (not $counter and scalar keys %element == 1 and
exists($element{'TYPE'})) {
my $table = "publisher";
if (exists($element{'table'})) {
$table = $element{'table'};
}
for my $term ( grep !/^(table|operator)$/, keys %element ) {
$sth->bind_param($counter, $element{$term},
{TYPE=>CBDB::DB::getType($table,$term)});
$counter++;
}
}
}
}
The getId( ), setId( ), getName( ), and setName( ) methods are typical object-oriented methods for accessing properties of the object. Example 9-8 demonstrates this.
#################################################
# getId( ) - Return Id for this publisher.
# Parameters: None.
# Returns: ID.
sub getId {
my $self = shift;
return $self->{Id};
}
#################################################
# setId( ) - Set Id for this publisher.
# Parameters: An Id number.
# Returns: Nothing.
sub setId {
my $self = shift;
my $pId = shift or die "publisher.setId( Id ) requires a value.";
$self->{Id} = $pId;
}
#################################################
# getName( ) - Return Name for this publisher.
# Parameters: None.
# Returns: Name.
sub getName {
my $self = shift;
return $self->{Name};
}
#################################################
# setName( ) - Set Name for this publisher.
# Parameters: A name.
# Returns: Nothing.
sub setName {
my $self = shift;
my $pName = shift || undef;
$self->{Name} = $pName;
}The getByPrimaryKey( ) method retrieves data by its primary key, invoking the get( ) method previously shown. This is shown in Example 9-9.
#################################################
# getByPrimaryKey() - Retrieves a single object from
# the database based on a primary key.
# Parameters: An Id.
# Returns: A Publisher object.
sub getByPrimaryKey {
my $pId = shift or die "publisher.get( )";
my $where = [ {'id' => $pId } ];
return ( get( $where, 1 ) )[0];
}The new( ) method is a typical, generic constructor, while the populate_publisher( ) method is used by the get( ) method to create a Publisher object. Example 9-10 shows constructors.
#################################################
# new( ) - Constructor.
# Example: CBDB::Publisher->new( );
# Returns: blessed hash.
sub new {
my $proto = shift;
my $class = ref($proto) || $proto;
my $self = {};
bless($self, $class);
return $self;
}
#################################################
# populate_publisher() - Return a publisher object
# populated from a result set.
# Parameters: Data from a DBI fetch.
# Returns: A Publisher object.
sub populate_publisher {
my $Ref = shift;
my $publisher = CBDB::Publisher->new( );
$publisher->setName($Ref->{publisher_name});
$publisher->setId($Ref->{publisher_id});
return $publisher;
}
1; # This always terminates a class definition.This class provides utility functions related to databases. It also invokes a database-specific class, mysql. It contains, as a static variable, a hash that lists all the columns in all the application's tables along with their data types.
Example 9-11 demonstrates the DB class.
package CBDB::DB;
use strict;
use BM::mysql;
my $VERSION = '0.1';
use constant DSN => "dbi:mysql:database=Books;host=localhost";
use constant USER => "andy";
use constant PASSWORD => "ALpswd";
my $types = {
'creator' => { 'name' => 1, 'id' => 4 },
'book' => { 'title' => 1, 'publisher_id' => 4, 'date' => 11, 'id' => 4 },
'book_creator' => { 'book_id' => 4, 'creator_id' => 4, 'role_id' => 4 },
'publisher' => { 'name' => 1, 'id' => 4 },
'role' => { 'name' => 1, 'id' => 4 },
};
#####################################################################
# getDB() - Returns a database handle connection for the database.
# Parameters: None.
# Returns: DBH Connection Handle.
sub getDB {
my $dbh = DBI->connect(DSN,USER,PASSWORD,{PrintError => 1,RaiseError => 1});
return $dbh;
}
#####################################################################
# get_pk_value() - Returns the most recent auto_increment value for a PK.
# Parameters: Database Handle.
# Returns: Primary key value.
sub get_pk_value {
my $dbh = shift or die "DB::get_pk_value needs a Database Handle...";
my $dbd = BM::mysql->new( );
return $dbd->get_pk_value( $dbh );
}
#####################################################################
# getType() - Returns the type of a column within a table.
# Parameters: Table name and column name.
# Returns: DBI Type code.
sub getType {
my $table = shift;
my $col = shift;
return $types->{$table}{$col};
}
1;In this class, we have tried to extract and isolate calls to methods that are specific to a particular database server.
Example 9-12 demonstrates the mysql class.
package BM::mysql;
use strict;
###############
# CONSTRUCTOR #
###############
sub new {
my $proto = shift;
my $class = ref($proto) || $proto;
my $self = { };
bless($self, $class);
return $self;
}
##################################################
# is_pk() - Determines if a column is a primary key.
# Parameters: DBI statement handle and a column
# number from that handle.
# Returns: true or false.
sub is_pk ($$$) {
my $self = shift;
my $sth = shift;
my $i = shift;
return 1 if $$sth->{mysql_is_pri_key}->[$i];
return 0;
}
###################################################
# is_auto_increment() - Determines if a column is an
# AUTO_INCREMENT column.
# Parameters: DBI statement.
# handle and a column number from that handle.
# Returns: true or false.
sub is_auto_increment($$$) {
my $self = shift;
my $sth = shift;
my $i = shift;
return 1 if $$sth->{mysql_is_auto_increment}->[$i];
return 0;
}
################################################
# get_pk_value() - Returns the last AUTO_INCREMENT
# value for this connection.
# Paramaters: DBI database handle.
# Returns: PK value.
sub get_pk_value {
my $self = shift;
my $dbh = shift or die "mysql::get_pk needs a Database Handle...";
my $mysqlPk = "Select last_insert_id( ) as pk";
my $mysqlSth = $dbh->prepare($mysqlPk);
$mysqlSth->execute( );
my $mysqlHR = $mysqlSth->fetchrow_hashref;
my $pk = $mysqlHR->{"pk"};
$mysqlSth->finish;
return $pk;
}
1;This class contains a static hash of all the Model objects used by the application. The cache is organized by class name (the first-order hash) and primary key (the second-order, or nested, hash).
Besides increasing performance, the cache also allows multiple objects to exist that represent the same row of data in the underlying table. Because each object's code uses references to the cached objects, the object automatically reflects changes made to other objects.
Example 9-13 demonstrates the Cache class.
package CBDB::Cache;
# This file keeps a copy of all active objects,
#s with records of their primary keys.
use strict;
my %cache = ( );
sub set {
$cache{$_[0]}{$_[1]} = $_[2];
}
sub get {
return $cache{$_[0]}{$_[1]};
}
sub has {
return exists $cache{$_[0]}{$_[1]};
}
1;
Now that we've seen the Model class and all its supporting classes, let's look at how it is used in practice. The following snippets of code would be part of the Controller layer of the application: the layer that performs all the logic. Note how all the actual database calls are hidden from this layer. It uses just calls to the Model class.
Each file in the Controller layer indicates that it will use the Publisher class:
use CBDB::Publisher; my $VERSION = 1.0;
A new object is created as follows:
my $pub = new CBDB::Publisher( );
Now let's set some data. The following creates a new publisher in our program (but not the database). We're in a hurry, so we can't be bothered with good spelling.
$pub->setName("Joe's Boks");Note that we didn't set the id field of the publisher. The ID is an auto-increment field taken care of automatically by the database. A more abstract way of understanding our approach is that the ID is not a real-world property of this object. It exists only because the object-relational model we're using internally requires it. Therefore, at the controller level, we don't have to worry about assigning it or making sure it's unique.
We'll see what we just created:
print 'Our new publisher is ' . $pub->getName( ) . "\n";
If the program were to terminate at this point, this object's data would be lost. To make it persistent, we need to save it to the database:
$pub->create( );
Now the object has been created in the database and can be retrieved by another application, or by our application during a subsequent run. The database has assigned a primary key, which we can store for later use to find the object again:
my $new_id = $pub->getId( );
Suppose we want to retrieve the object in another part of our program. We'll use the getByPrimaryKey( ) call with the ID we stored earlier. The getByPrimaryKey( ) is static; we call it on the Publisher class itself instead of on an object from that class.
my $pub2 = CBDB::Publisher::getByPrimaryKey($new_id);
Because of the caching mechanism, $pub2 is the same object in memory as $pub. We can check this identity, if we're curious.
if ($pub2 != $pub) {
print "Whoops! Something isn't working right!\n"
}Let's change some data. For instance, we can fix the typo we introduced at the beginning of this section.
$pub2->setName("Joe's Books");At this point, the data has been changed in the object only, not in the underlying database. However, because all active instances of this object in our program are references to the same object, this change takes place everywhere in the application immediately. Thus, the following statement will print Joe's Books, not Joe's Boks, even though we didn't explicitly touch the data to which $pub points.
print "The publisher's name is now " . $pub->getName( ) . "\n";
Now let's save these changes to the database. We can use either $pub or $pub2 to indicate the data.
$pub2->update( );
Later, we decide we're finished with this data and need to delete the row from the database.
$pub->remove( );
The underlying row in the database has now been deleted. However, this object (as well as $pub2) still contains the data until the program terminates or destroys the objects. This may be useful in case we want to refer to some property that the publisher used to have, as we do in the informational message below.
print "The publisher " . $pub->getName( ) . " was just erased.\n";
We hope that this little tour has shown the value of planning your program's structure so it is flexible and maintainable. Underneath DBI and CGI and the MVC methodology, it's just a bunch of INSERT, SELECT, and other SQL statements.
|  | |
| 9.2. DBI and CGI |  | 10. Python |

Copyright © 2003 O'Reilly & Associates. All rights reserved.